
merge develop into master 20231220
Showing
docs/ide-settings.md
0 → 100644
{kind=link}
98.8 KB
{kind=link}

7.8 KB
{kind=link}
167.7 KB
{kind=link}
112.5 KB
{kind=link}
103.8 KB
{kind=link}
66.2 KB
{kind=link}

78.3 KB
{kind=link}
42.4 KB
{kind=link}
33.7 KB
{kind=link}
64.3 KB
{kind=link}

27.6 KB
{kind=link}
8.8 KB
{kind=link}

62.6 KB
{kind=link}

30.8 KB
{kind=link}
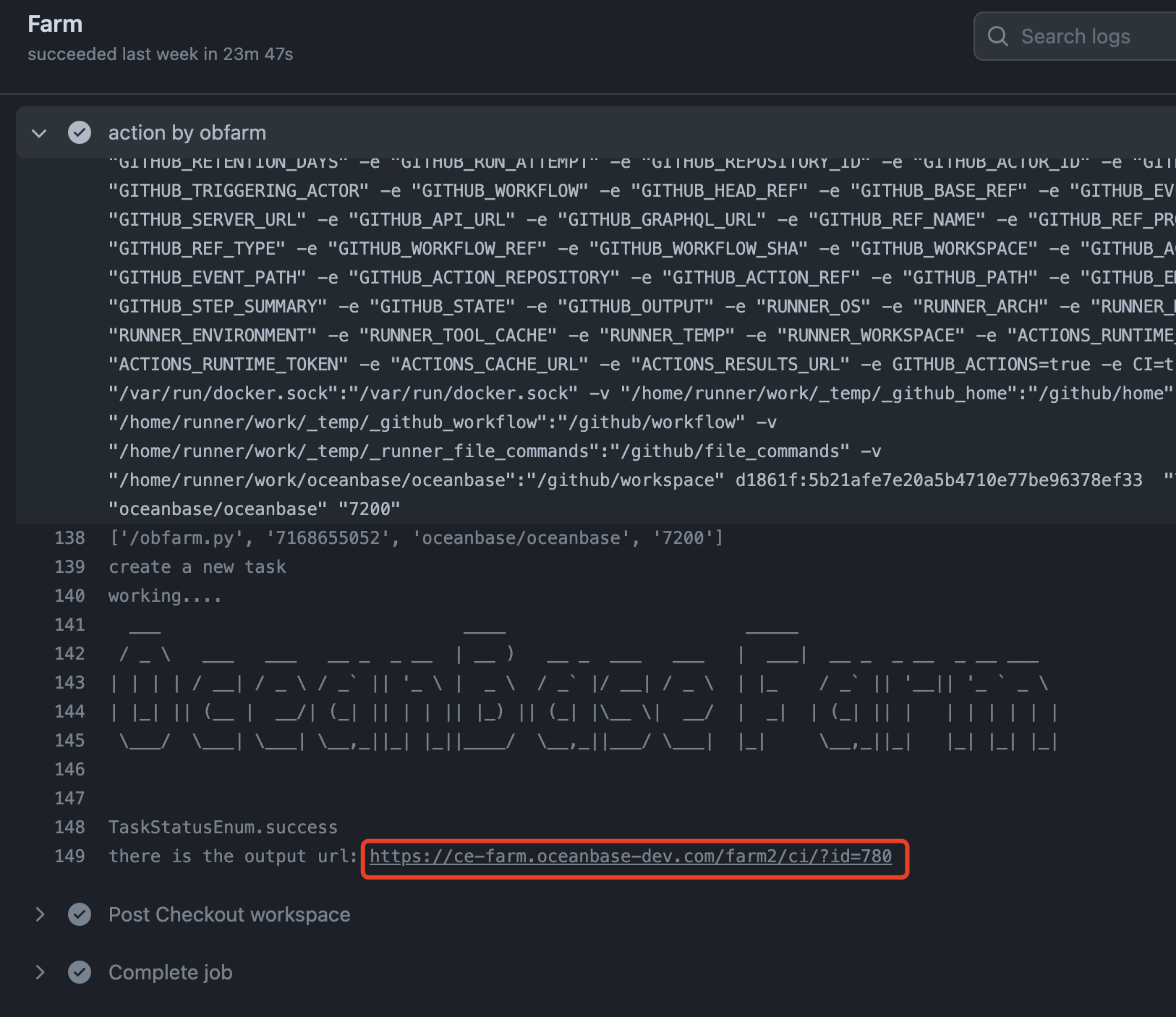
326.3 KB
{kind=link}
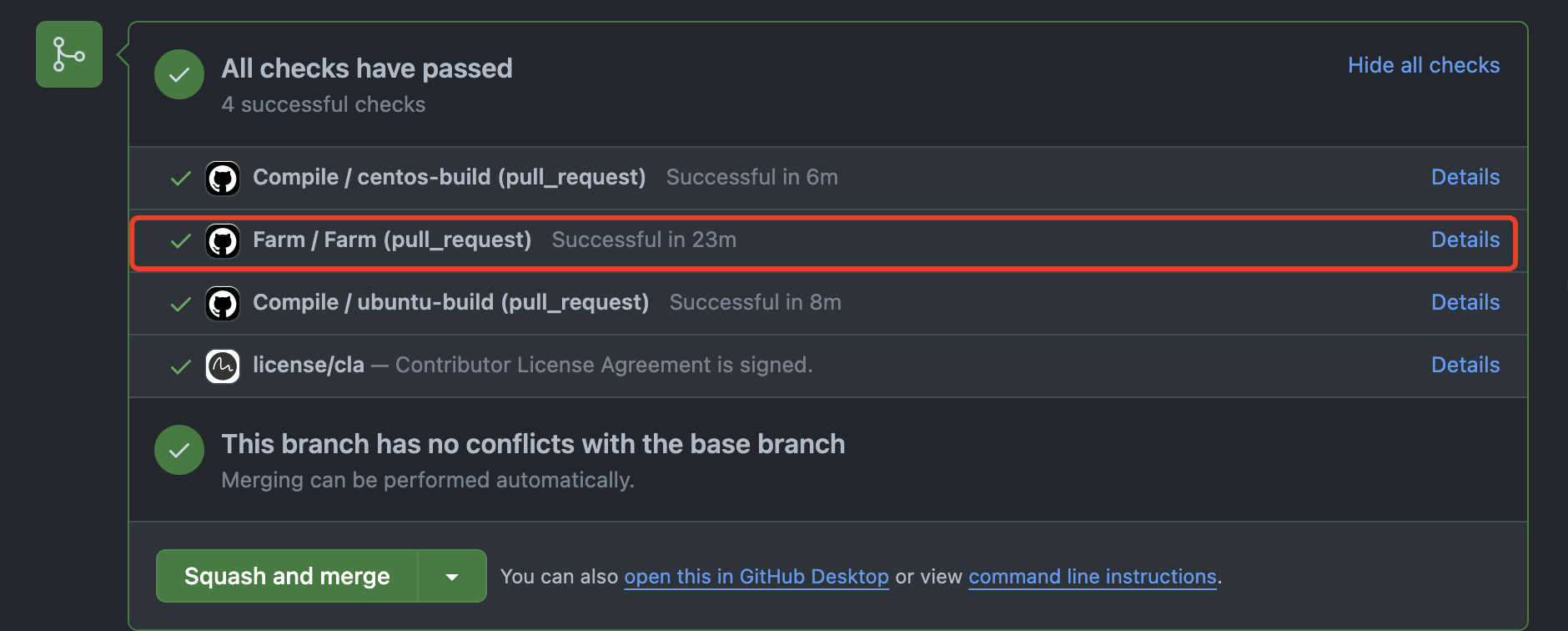
158.9 KB
docs/images/unittest-unittest.png
0 → 100644
{kind=link}

39.1 KB
docs/logging.md
0 → 100644
此差异已折叠。
docs/memory.md
0 → 100644
docs/unittest.md
0 → 100644
{kind=link}
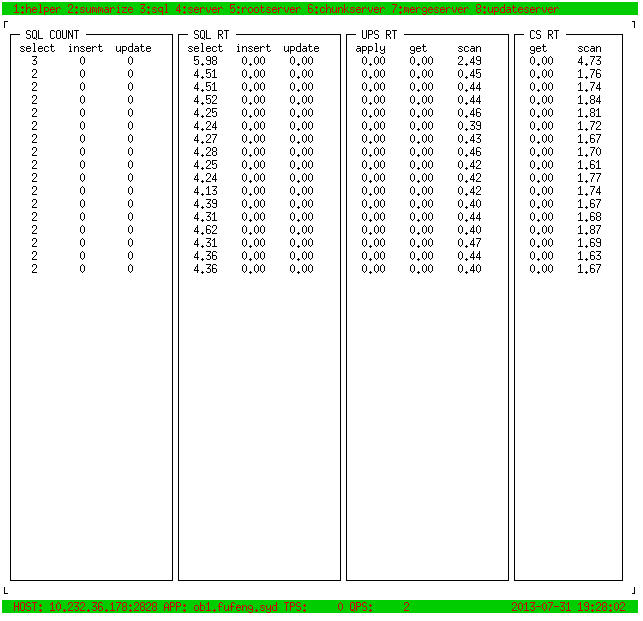
20.7 KB
{kind=link}
16.3 KB
{kind=link}
11.6 KB
{kind=link}

15.2 KB
{kind=link}
16.8 KB
{kind=link}
150.4 KB
{kind=link}
69.5 KB
{kind=link}
138.5 KB
{kind=link}
67.9 KB
{kind=link}
141.0 KB
{kind=link}
52.6 KB
{kind=link}
86.8 KB
{kind=link}
105.7 KB
{kind=link}
38.4 KB
{kind=link}

32.0 KB
{kind=link}

34.4 KB
{kind=link}
131.0 KB
{kind=link}
109.9 KB