more speech docs (#606)
* add speech related docs: tts, text front end, ngram lm, corrector * format doc * mergify with doc
Showing
docs/images/prosody.jpeg
0 → 100644
{kind=link}
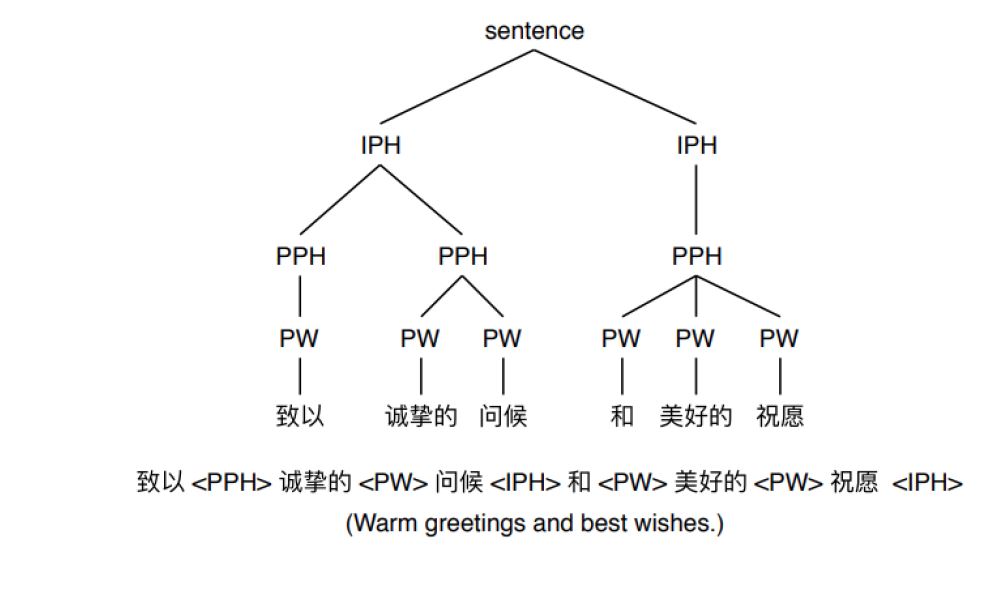
47.1 KB
docs/src/speech_synthesis.md
0 → 100644