Dygraph (#436)
* fix pretrain reader encoding * dygraph * update bce * fix readme * update readme * fix readme * remove debug log * remove chn example * fix pretrain * tokenizer can escape special token rename mlm_bias * update readme * 1. MRC tasks 2. optimize truncate strategy in tokenzier 3. rename `ernie.cls_fc` to `ernie.classifyer` 4. reorg pretrain dir * + doc string * update readme * Update README.md * Update README.md * Update README.md * update pretrain * Update README.md * show gif * update readme * fix gif; disable save_dygrpah * bugfix * + save inf model + inference + distill + readme * Update README.md * + propeller server * Update README.md * Update README.md * Update README.md * + sementic analysis(another text classification) * transformer + cache fix tokenization bug * update reamde; fix tokenization * Update README.md * Update README.md * Add files via upload * Update README.md * Update README.md * Update README.md * infer senti analysis * + readme header * transformer cache has gradients * + seq2seq * +experimental * reorg * update readme * Update README.md * seq2seq * + cnndm evluation scripts * update README.md * +zh readme * + publish ernie gen model * update README.md * Update README.zh.md * Update README.md * Update README.zh.md * Update README.md * Update README.zh.md * Update README.md * Update README.zh.md * Update README.md * Update README.zh.md * Update README.zh.md * Add files via upload * Update README.md * Update README.zh.md * Add files via upload * release ernie-gen (#444) * release ernie-gen * add .meta * del tag * fix tag * Add files via upload * Update README.zh.md * Update README.md * Update and rename README.zh.md to README.eng.md * Update README.eng.md * Update README.md * Update README.eng.md * Update README.md * Update README.eng.md * Update README.md * Update README.md * Update README.md * Update README.eng.md * Update README.eng.md * Update README.eng.md * Update README.md * Update README.md * Update README.md * Update README.md Co-authored-by: Nkirayummy <shi.k.feng@gmail.com> Co-authored-by: Nzhanghan <zhanghan17@baidu.com>
Showing
.metas/ERNIE_milestone.png
0 → 100644
{kind=link}
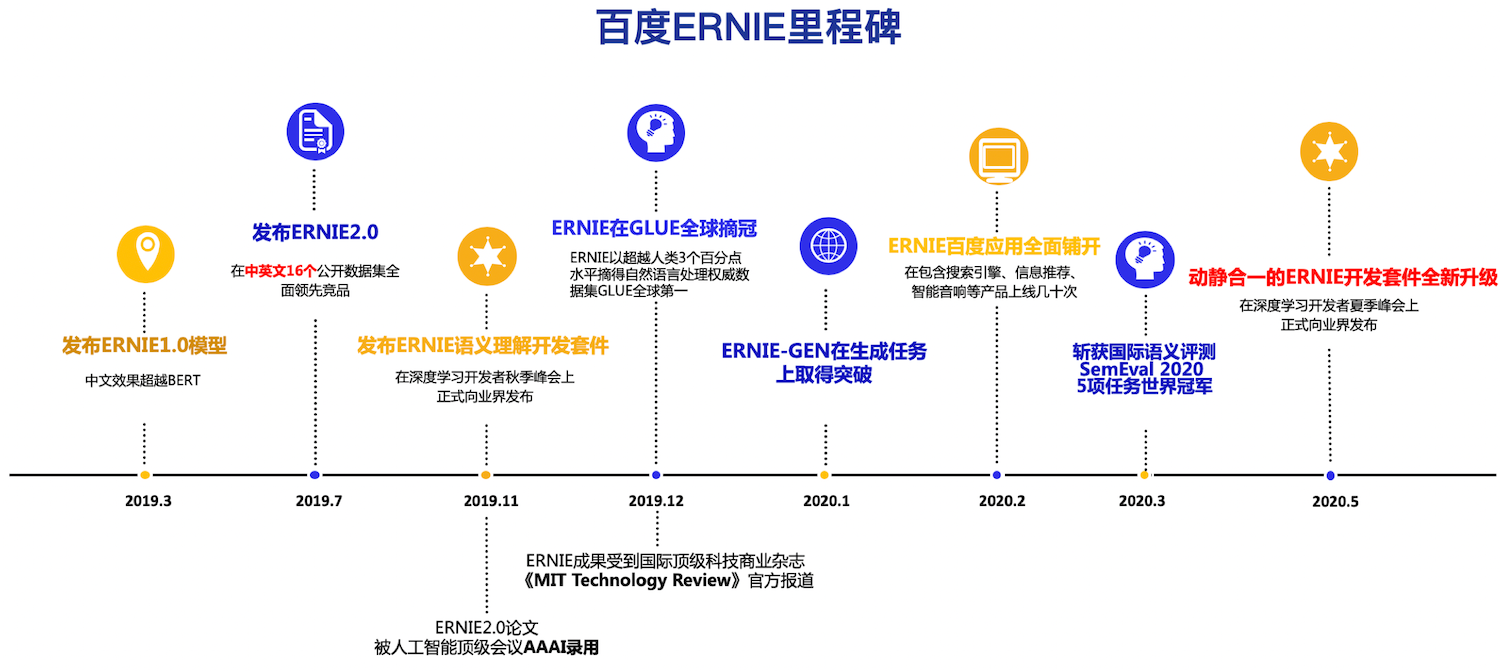
693.0 KB
.metas/ERNIE_milestone_chn.png
0 → 100644
{kind=link}
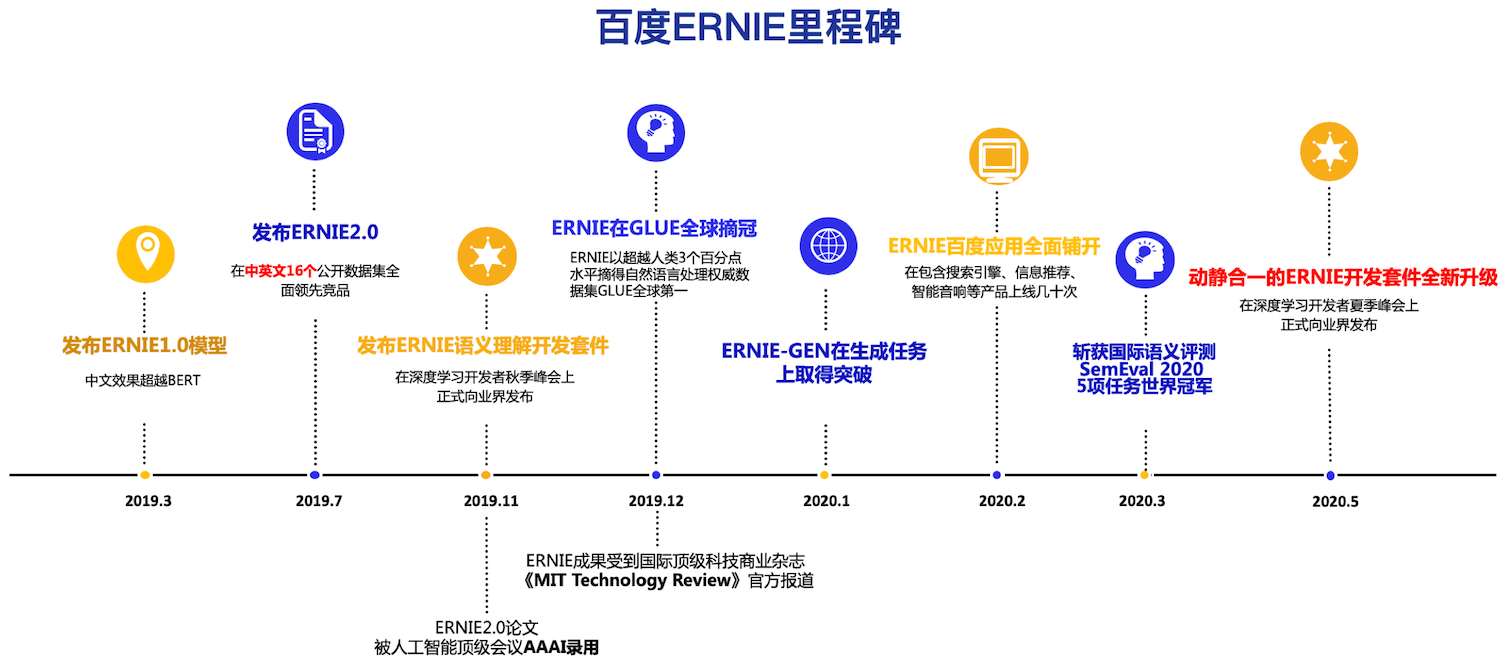
693.0 KB
.metas/dygraph_show.gif
0 → 100644
{kind=link}
1.3 MB
.metas/ernie-head-banner.gif
0 → 100644
{kind=link}

2.6 MB
.metas/ernie.png
0 → 100644
{kind=link}

332.8 KB
.metas/ernie2.0_arch.png
已删除
100644 → 0
{kind=link}
303.4 KB
.metas/ernie2.0_model.png
已删除
100644 → 0
{kind=link}
169.8 KB
.metas/ernie2.0_paper.png
已删除
100644 → 0
{kind=link}

94.9 KB
.metas/ernie_tiny.png
已删除
100644 → 0
{kind=link}
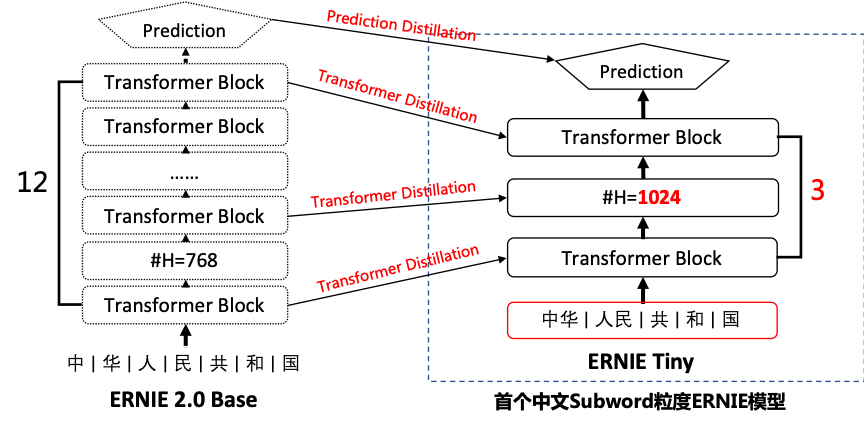
99.0 KB
.pre-commit-config.yaml
已删除
100644 → 0
.run_ce.sh
已删除
100644 → 0
.style.yapf
已删除
100644 → 0
.travis.yml
已删除
100644 → 0
.travis/precommit.sh
已删除
100755 → 0
LICENSE
已删除
100644 → 0
README.eng.md
0 → 100644
此差异已折叠。
README.zh.md
已删除
100644 → 0
此差异已折叠。
config/ernie_config.json
已删除
100644 → 0
config/vocab.txt
已删除
100644 → 0
此差异已折叠。
config/vocab_en.txt
已删除
100644 → 0
此差异已折叠。
data/demo_train_set.gz
已删除
100644 → 0
文件已删除
data/demo_valid_set.gz
已删除
100644 → 0
文件已删除
data/train_filelist
已删除
100644 → 0
data/valid_filelist
已删除
100644 → 0
demo/finetune_classifier.py
0 → 100644
demo/finetune_mrc_dygraph.py
0 → 100644
demo/finetune_ner_dygraph.py
0 → 100644
demo/mrc/mrc_reader.py
0 → 100644
此差异已折叠。
demo/pretrain/README.md
0 → 100644
demo/pretrain/pretrain.py
0 → 100644
此差异已折叠。
demo/pretrain/pretrain_dygraph.py
0 → 100644
此差异已折叠。
distill/distill.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ernie/_ce.py
已删除
100644 → 0
此差异已折叠。
ernie/batching.py
已删除
100644 → 0
此差异已折叠。
ernie/ernie_encoder.py
已删除
100644 → 0
此差异已折叠。
ernie/file_utils.py
0 → 100644
此差异已折叠。
ernie/finetune/classifier.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
ernie/finetune_args.py
已删除
100644 → 0
此差异已折叠。
ernie/finetune_launch.py
已删除
100644 → 0
此差异已折叠。
ernie/infer_classifyer.py
已删除
100644 → 0
此差异已折叠。
ernie/model/ernie.py
已删除
100644 → 0
此差异已折叠。
ernie/model/ernie_v1.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
ernie/modeling_ernie.py
0 → 100644
此差异已折叠。
此差异已折叠。
ernie/pretrain_args.py
已删除
100644 → 0
此差异已折叠。
ernie/pretrain_launch.py
已删除
100644 → 0
此差异已折叠。
ernie/reader/pretraining.py
已删除
100644 → 0
此差异已折叠。
ernie/reader/task_reader.py
已删除
100644 → 0
此差异已折叠。
ernie/run_classifier.py
已删除
100644 → 0
此差异已折叠。
ernie/run_mrc.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
ernie/service/client.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
ernie/tokenization.py
已删除
100644 → 0
此差异已折叠。
ernie/tokenizing_ernie.py
0 → 100644
此差异已折叠。
ernie/train.py
已删除
100644 → 0
此差异已折叠。
ernie/utils/__init__.py
已删除
100644 → 0
ernie/utils/args.py
已删除
100644 → 0
此差异已折叠。
ernie/utils/cmrc2018_eval.py
已删除
100644 → 0
此差异已折叠。
ernie/utils/data.py
已删除
100644 → 0
此差异已折叠。
ernie/utils/fp16.py
已删除
100644 → 0
此差异已折叠。
ernie/utils/init.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
example/finetune_ner.py
已删除
100644 → 0
此差异已折叠。
example/finetune_ranker.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
experimental/seq2seq/README.md
0 → 100644
此差异已折叠。
experimental/seq2seq/decode.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
propeller/README.en.md
已删除
100644 → 0
此差异已折叠。
propeller/README.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
script/zh_task/pretrain.sh
已删除
100644 → 0
此差异已折叠。
setup.py
0 → 100644
此差异已折叠。