LiftSim A2C baseline (#209)
* liftsim a2c baseline * update readme * compatible with different os * empty * refine comments * remove unnecessary assertion; add tensorboard guide * remove unnecessary assertion * update parl dependence of A2C
Showing
{kind=link}

592.7 KB
{kind=link}
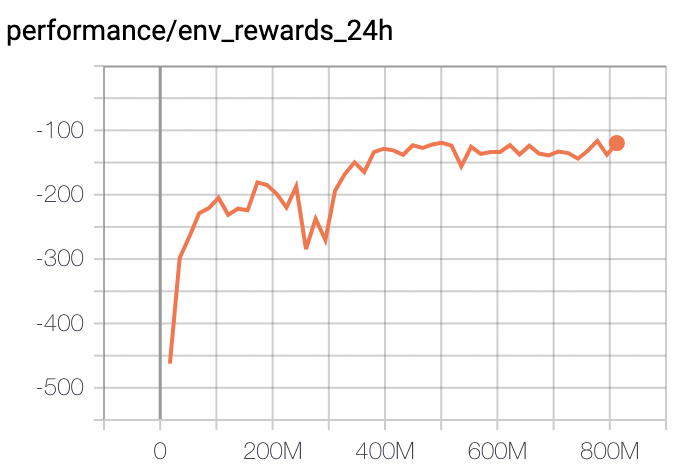
129.3 KB
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动