Update docs (#6)
* update docs
Showing
images/fc_computing.png
0 → 100644
{kind=link}
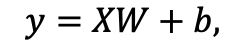
11.8 KB
images/fc_computing_block.png
0 → 100644
{kind=link}
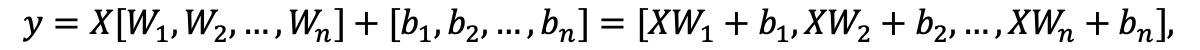
39.4 KB
{kind=link}
26.4 KB
images/softmax_computing.png
0 → 100644
{kind=link}
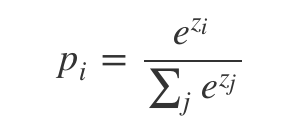
9.7 KB