Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleClas
提交
180f32e4
P
PaddleClas
项目概览
PaddlePaddle
/
PaddleClas
8 个月 前同步成功
通知
115
Star
4999
Fork
1114
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
19
列表
看板
标记
里程碑
合并请求
6
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleClas
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
19
Issue
19
列表
看板
标记
里程碑
合并请求
6
合并请求
6
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
180f32e4
编写于
5月 09, 2020
作者:
littletomatodonkey
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add fp16 pngs
上级
0e807423
变更
12
隐藏空白更改
内联
并排
Showing
12 changed file
with
15 addition
and
4 deletion
+15
-4
docs/images/models/T4_benchmark/t4.fp16.bs1.EfficientNet.png
docs/images/models/T4_benchmark/t4.fp16.bs1.EfficientNet.png
+0
-0
docs/images/models/T4_benchmark/t4.fp16.bs4.DPN.png
docs/images/models/T4_benchmark/t4.fp16.bs4.DPN.png
+0
-0
docs/images/models/T4_benchmark/t4.fp16.bs4.HRNet.png
docs/images/models/T4_benchmark/t4.fp16.bs4.HRNet.png
+0
-0
docs/images/models/T4_benchmark/t4.fp16.bs4.Inception.png
docs/images/models/T4_benchmark/t4.fp16.bs4.Inception.png
+0
-0
docs/images/models/T4_benchmark/t4.fp16.bs4.ResNet.png
docs/images/models/T4_benchmark/t4.fp16.bs4.ResNet.png
+0
-0
docs/images/models/T4_benchmark/t4.fp16.bs4.SeResNeXt.png
docs/images/models/T4_benchmark/t4.fp16.bs4.SeResNeXt.png
+0
-0
docs/zh_CN/models/DPN_DenseNet.md
docs/zh_CN/models/DPN_DenseNet.md
+2
-0
docs/zh_CN/models/EfficientNet_and_ResNeXt101_wsl.md
docs/zh_CN/models/EfficientNet_and_ResNeXt101_wsl.md
+3
-2
docs/zh_CN/models/HRNet.md
docs/zh_CN/models/HRNet.md
+3
-1
docs/zh_CN/models/Inception.md
docs/zh_CN/models/Inception.md
+2
-0
docs/zh_CN/models/ResNet_and_vd.md
docs/zh_CN/models/ResNet_and_vd.md
+2
-0
docs/zh_CN/models/SEResNext_and_Res2Net.md
docs/zh_CN/models/SEResNext_and_Res2Net.md
+3
-1
未找到文件。
docs/images/models/T4_benchmark/t4.fp16.bs1.EfficientNet.png
0 → 100644
浏览文件 @
180f32e4
88.5 KB
docs/images/models/T4_benchmark/t4.fp16.bs4.DPN.png
0 → 100644
浏览文件 @
180f32e4
57.3 KB
docs/images/models/T4_benchmark/t4.fp16.bs4.HRNet.png
0 → 100644
浏览文件 @
180f32e4
54.4 KB
docs/images/models/T4_benchmark/t4.fp16.bs4.Inception.png
0 → 100644
浏览文件 @
180f32e4
57.1 KB
docs/images/models/T4_benchmark/t4.fp16.bs4.ResNet.png
0 → 100644
浏览文件 @
180f32e4
83.9 KB
docs/images/models/T4_benchmark/t4.fp16.bs4.SeResNeXt.png
0 → 100644
浏览文件 @
180f32e4
105.3 KB
docs/zh_CN/models/DPN_DenseNet.md
浏览文件 @
180f32e4
...
...
@@ -12,6 +12,8 @@ DPN的全称是Dual Path Networks,即双通道网络。该网络是由DenseNet


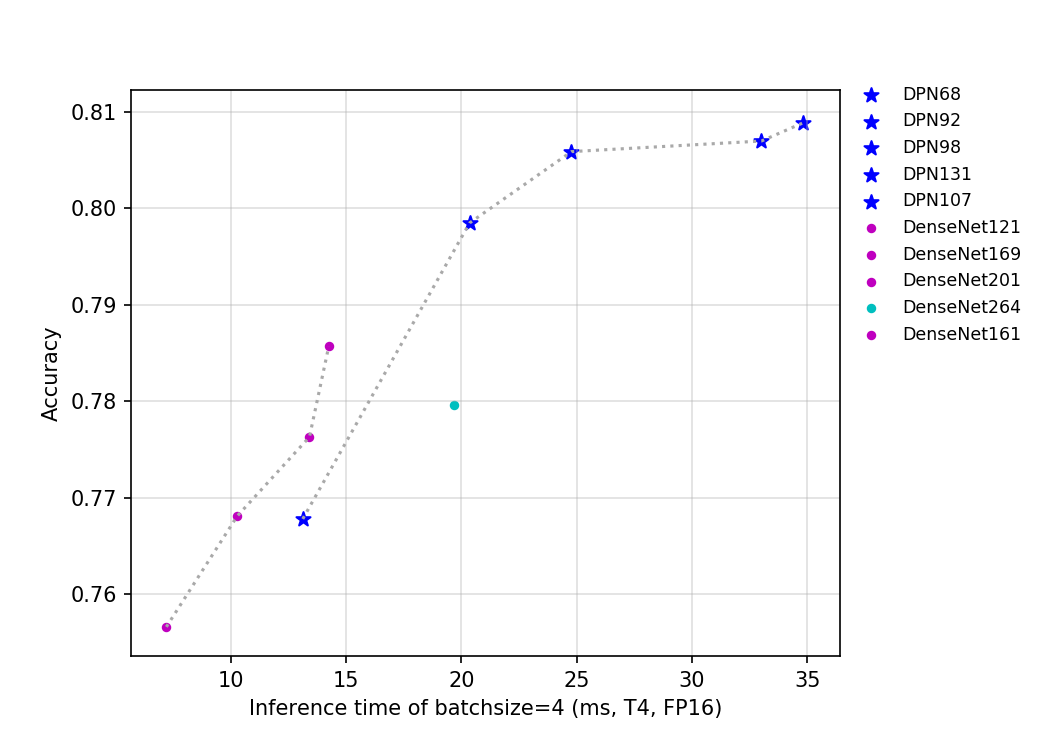
目前PaddleClas开源的这两类模型的预训练模型一共有10个,其指标如上图所示,可以看到,在相同的FLOPS和参数量下,相比DenseNet,DPN拥有更高的精度。但是由于DPN有更多的分支,所以其推理速度要慢于DenseNet。由于DenseNet264的网络层数最深,所以该网络是DenseNet系列模型中参数量最大的网络,DenseNet161的网络的宽度最大,导致其是该系列中网络中计算量最大、精度最高的网络。从推理速度来看,计算量大且精度高的的DenseNet161比DenseNet264具有更快的速度,所以其比DenseNet264具有更大的优势。
对于DPN系列网络,模型的FLOPS和参数量越大,模型的精度越高。其中,由于DPN107的网络宽度最大,所以其是该系列网络中参数量与计算量最大的网络。
...
...
docs/zh_CN/models/EfficientNet_and_ResNeXt101_wsl.md
浏览文件 @
180f32e4
...
...
@@ -6,8 +6,7 @@ EfficientNet是Google于2019年发布的一个基于NAS的轻量级网络,其
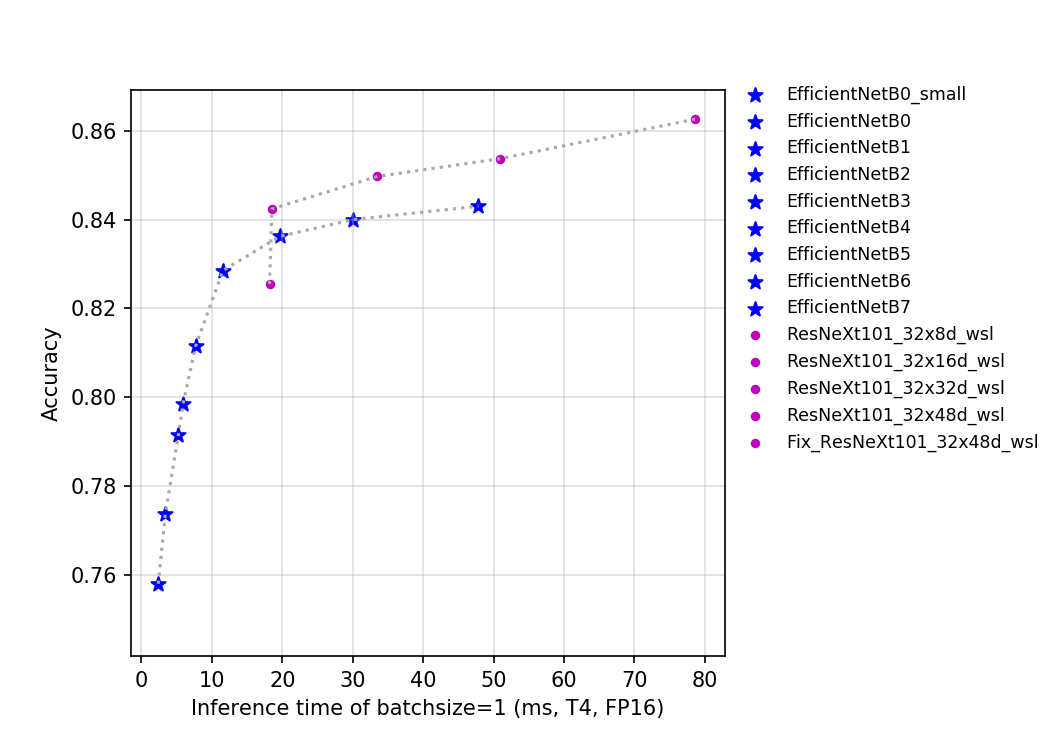
ResNeXt是facebook于2016年提出的一种对ResNet的改进版网络。在2019年,facebook通过弱监督学习研究了该系列网络在ImageNet上的精度上限,为了区别之前的ResNeXt网络,该系列网络的后缀为wsl,其中wsl是弱监督学习(weakly-supervised-learning)的简称。为了能有更强的特征提取能力,研究者将其网络宽度进一步放大,其中最大的ResNeXt101_32x48d_wsl拥有8亿个参数,将其在9.4亿的弱标签图片下训练并在ImageNet-1k上做finetune,最终在ImageNet-1k的top-1达到了85.4%,这也是迄今为止在ImageNet-1k的数据集上以224x224的分辨率下精度最高的网络。Fix-ResNeXt中,作者使用了更大的图像分辨率,针对训练图片和验证图片数据预处理不一致的情况下做了专门的Fix策略,并使得ResNeXt101_32x48d_wsl拥有了更高的精度,由于其用到了Fix策略,故命名为Fix-ResNeXt101_32x48d_wsl。
该系列模型的FLOPS、参数量以及T4 GPU
上的预测耗时如下图所示。
该系列模型的FLOPS、参数量以及T4 GPU上的预测耗时如下图所示。

...
...
@@ -15,6 +14,8 @@ ResNeXt是facebook于2016年提出的一种对ResNet的改进版网络。在2019


目前PaddleClas开源的这两类模型的预训练模型一共有14个。从上图中可以看出EfficientNet系列网络优势非常明显,ResNeXt101_wsl系列模型由于用到了更多的数据,最终的精度也更高。EfficientNet_B0_Small是去掉了SE_block的EfficientNet_B0,其具有更快的推理速度。
## 精度、FLOPS和参数量
...
...
docs/zh_CN/models/HRNet.md
浏览文件 @
180f32e4
...
...
@@ -3,7 +3,7 @@
## 概述
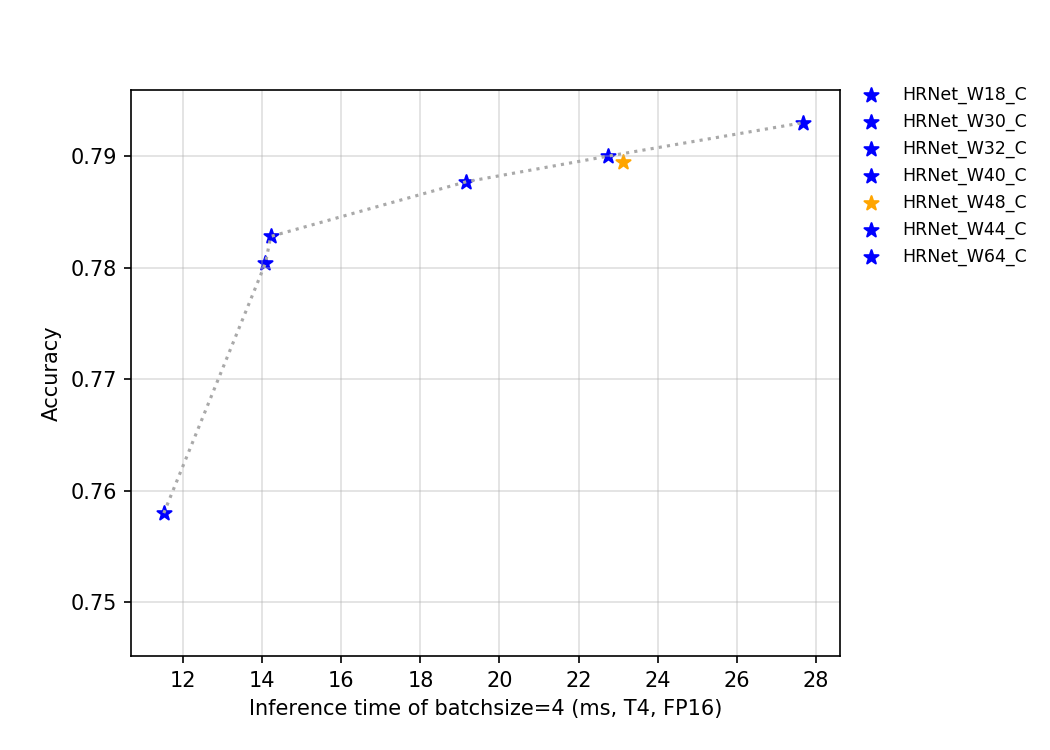
HRNet是2019年由微软亚洲研究院提出的一种全新的神经网络,不同于以往的卷积神经网络,该网络在网络深层仍然可以保持高分辨率,因此预测的关键点热图更准确,在空间上也更精确。此外,该网络在对分辨率敏感的其他视觉任务中,如检测、分割等,表现尤为优异。
该系列模型的FLOPS、参数量以及
FP32
预测耗时如下图所示。
该系列模型的FLOPS、参数量以及
T4 GPU上的
预测耗时如下图所示。

...
...
@@ -11,6 +11,8 @@ HRNet是2019年由微软亚洲研究院提出的一种全新的神经网络,


目前PaddleClas开源的这类模型的预训练模型一共有7个,其指标如图所示,其中HRNet_W48_C指标精度异常的原因可能是因为网络训练的正常波动。
...
...
docs/zh_CN/models/Inception.md
浏览文件 @
180f32e4
...
...
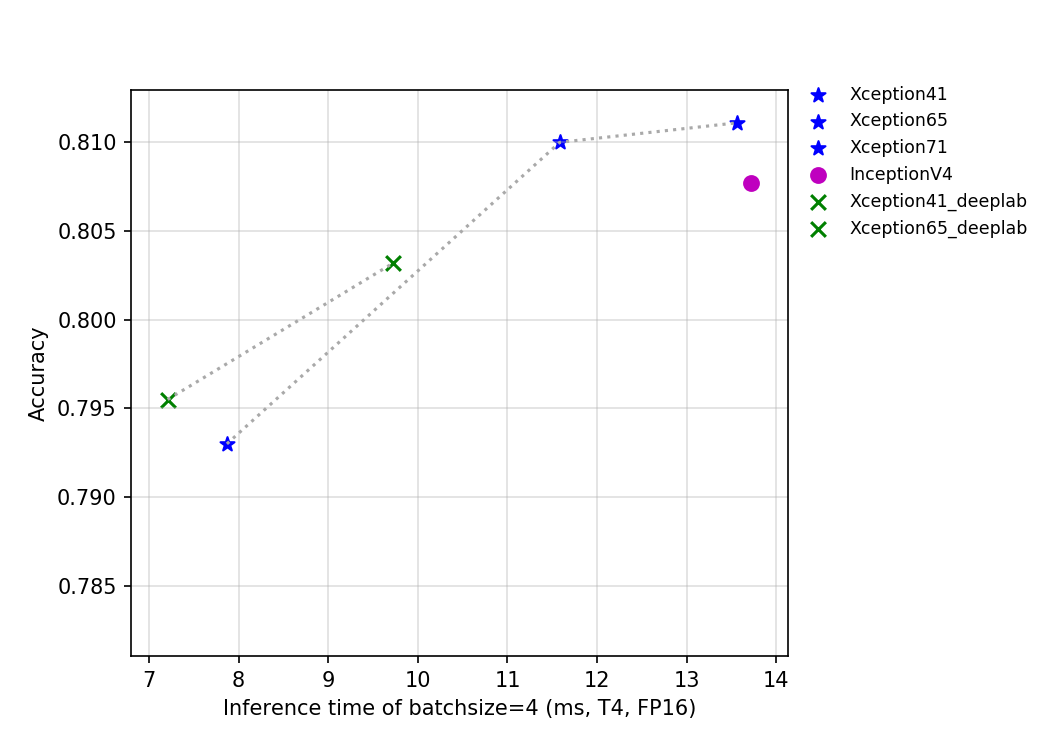
@@ -17,6 +17,8 @@ InceptionV4是2016年由Google设计的新的神经网络,当时残差结构


上图反映了Xception系列和InceptionV4的精度和其他指标的关系。其中Xception_deeplab与论文结构保持一致,Xception是PaddleClas的改进模型,在预测速度基本不变的情况下,精度提升约0.6%。关于该改进模型的详细介绍正在持续更新中,敬请期待。
...
...
docs/zh_CN/models/ResNet_and_vd.md
浏览文件 @
180f32e4
...
...
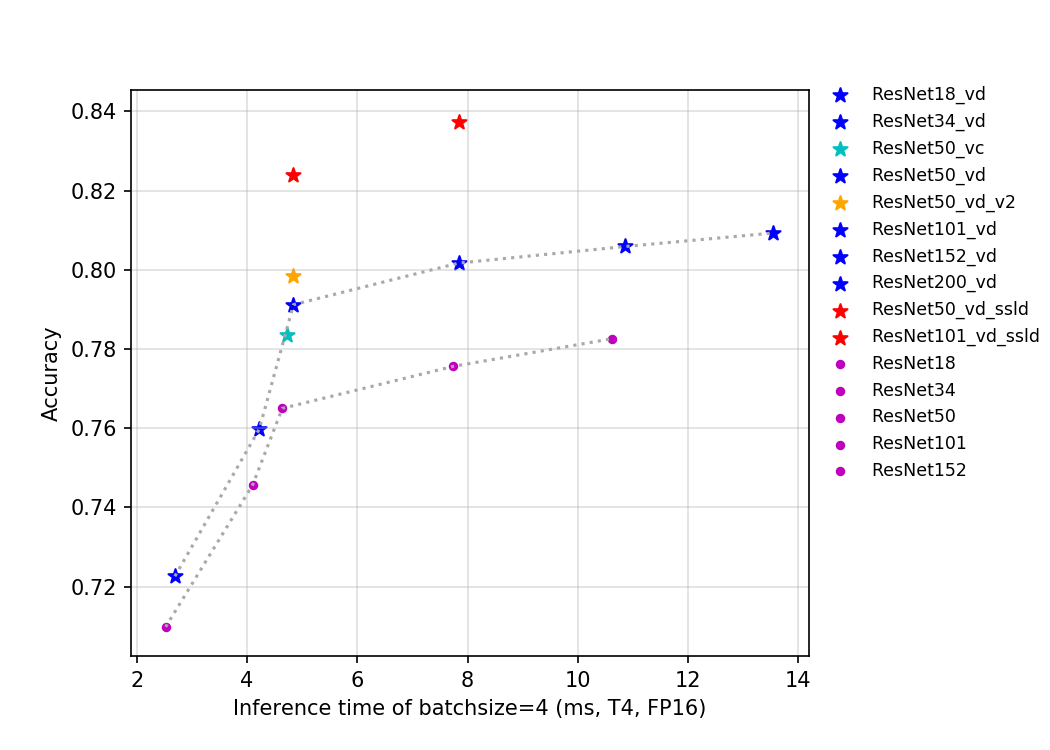
@@ -18,6 +18,8 @@ ResNet系列模型是在2015年提出的,一举在ILSVRC2015比赛中取得冠


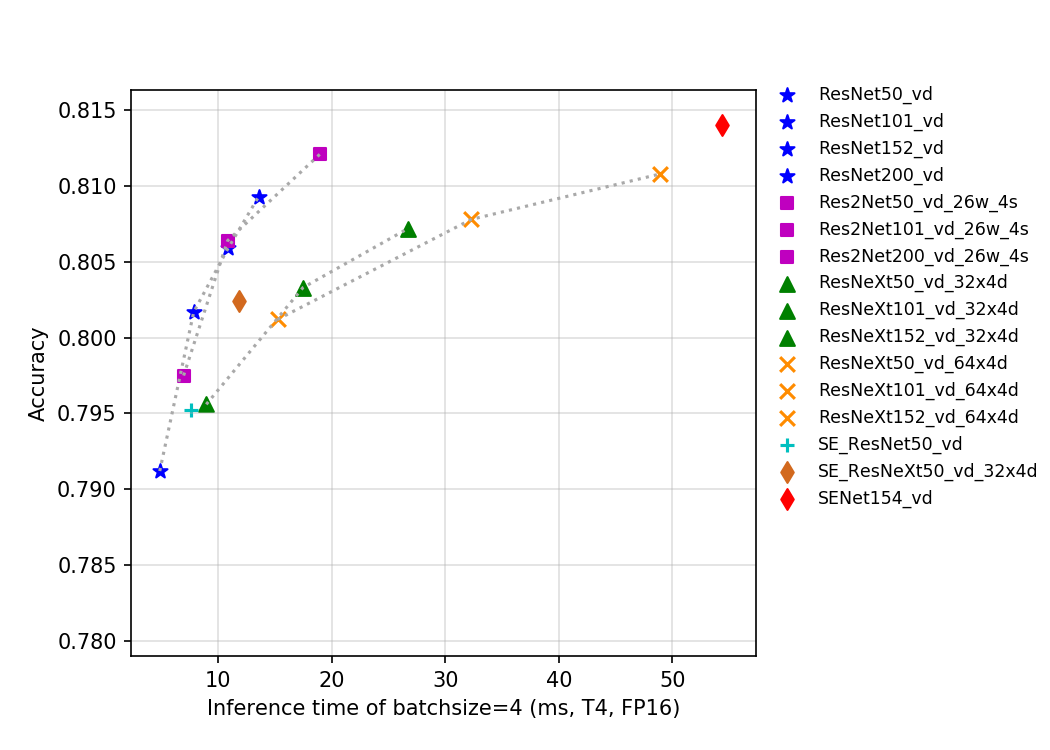
通过上述曲线可以看出,层数越多,准确率越高,但是相应的参数量、计算量和延时都会增加。ResNet50_vd_ssld通过用更强的teacher和更多的数据,将其在ImageNet-1k上的验证集top-1精度进一步提高,达到了82.39%,刷新了ResNet50系列模型的精度。
...
...
docs/zh_CN/models/SEResNext_and_Res2Net.md
浏览文件 @
180f32e4
...
...
@@ -7,7 +7,7 @@ SENet是2017年ImageNet分类比赛的冠军方案,其提出了一个全新的
Res2Net是2019年提出的一种全新的对ResNet的改进方案,该方案可以和现有其他优秀模块轻松整合,在不增加计算负载量的情况下,在ImageNet、CIFAR-100等数据集上的测试性能超过了ResNet。Res2Net结构简单,性能优越,进一步探索了CNN在更细粒度级别的多尺度表示能力。Res2Net揭示了一个新的提升模型精度的维度,即scale,其是除了深度、宽度和基数的现有维度之外另外一个必不可少的更有效的因素。该网络在其他视觉任务如目标检测、图像分割等也有相当不错的表现。
该系列模型的FLOPS、参数量以及T4 GPU上的
FP32
预测耗时如下图所示。
该系列模型的FLOPS、参数量以及T4 GPU上的预测耗时如下图所示。

...
...
@@ -16,6 +16,8 @@ Res2Net是2019年提出的一种全新的对ResNet的改进方案,该方案可


目前PaddleClas开源的这三类的预训练模型一共有24个,其指标如图所示,从图中可以看出,在同样Flops和Params下,改进版的模型往往有更高的精度,但是推理速度往往不如ResNet系列。另一方面,Res2Net表现也较为优秀,相比ResNeXt中的group操作、SEResNet中的SE结构操作,Res2Net在相同Flops、Params和推理速度下往往精度更佳。
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}