update to v2.4.0
Showing
此差异已折叠。
此差异已折叠。
{kind=link}
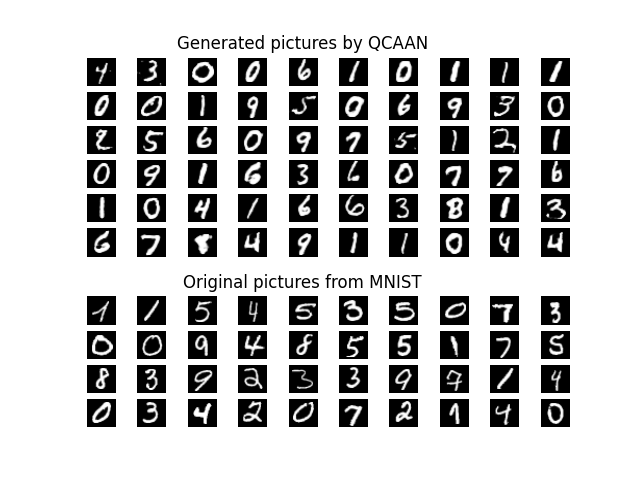
85.2 KB
此差异已折叠。
此差异已折叠。
文件已添加
文件已添加
{kind=link}
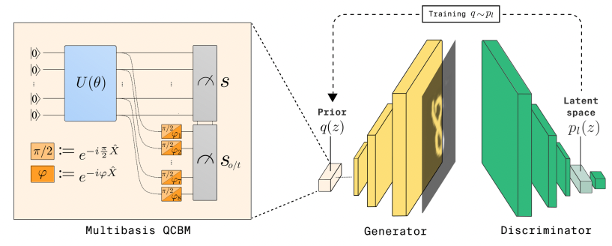
140.5 KB
{kind=link}
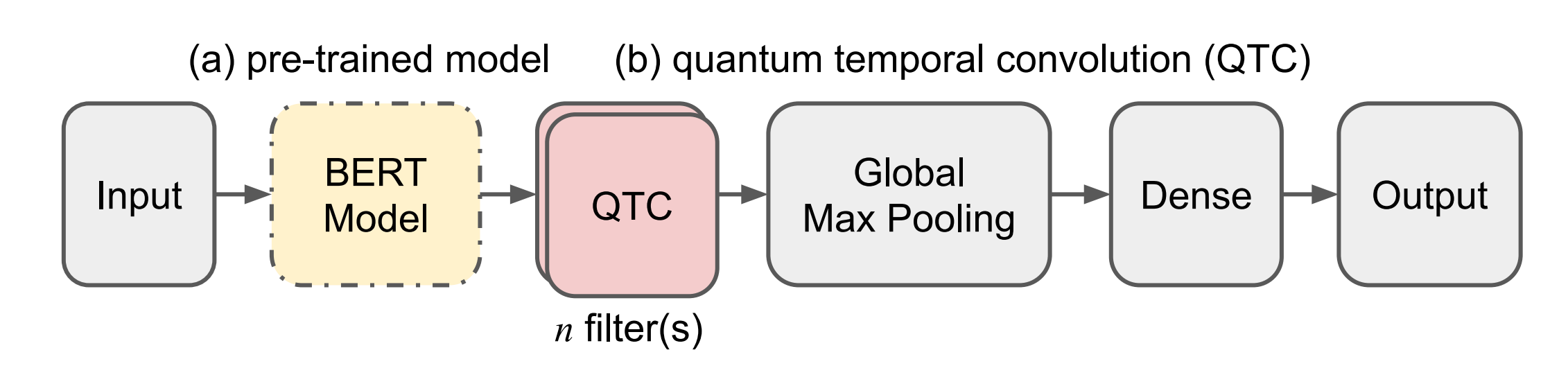
116.7 KB
文件已添加
此差异已折叠。
{kind=link}
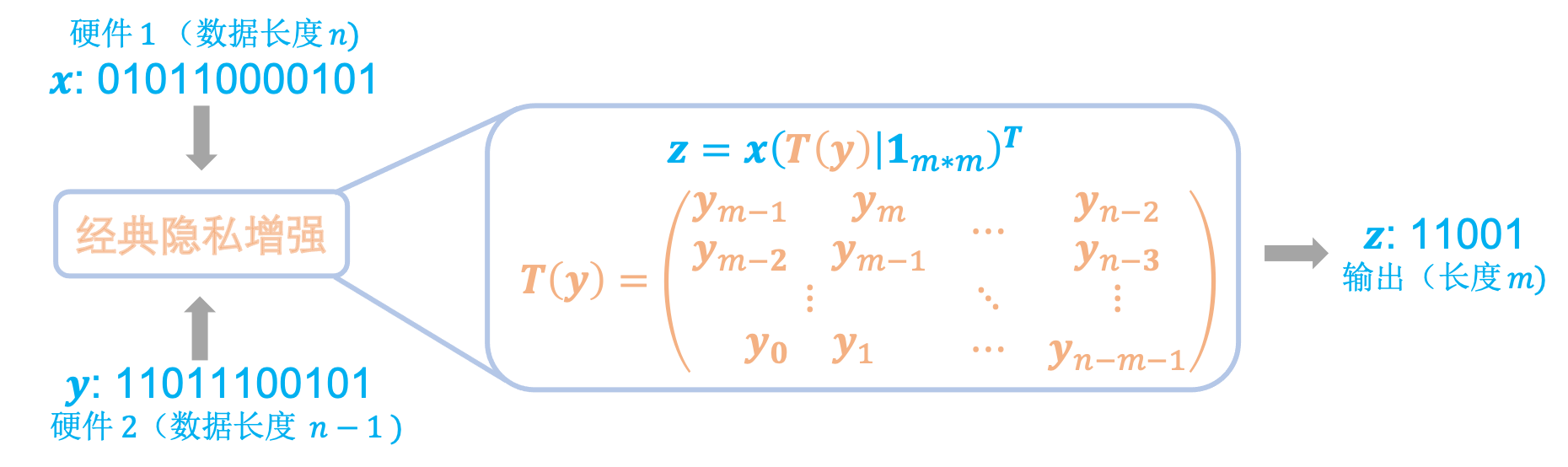
125.9 KB
{kind=link}

111.9 KB
此差异已折叠。
{kind=link}

73.5 KB
{kind=link}
57.9 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle_quantum/ansatz/layer.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle_quantum/gate/layer.py
已删除
100644 → 0
此差异已折叠。
paddle_quantum/gate/matrix.py
0 → 100644
此差异已折叠。
paddle_quantum/qml/bert_qtc.py
0 → 100644
此差异已折叠。
paddle_quantum/qml/qcaan.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。