update to v2.0.0
Showing
{kind=link}
150.3 KB
| paddlepaddle==1.8.5 | ||
| networkx>=2.4 | ||
| matplotlib>=3.3.0 | ||
| interval>=1.0.0 | ||
| progressbar>=2.5 | ||
| \ No newline at end of file | ||
| paddlepaddle>=2.0.1 | ||
| scipy | ||
| networkx | ||
| matplotlib | ||
| interval | ||
| tqdm | ||
| \ No newline at end of file |
{kind=link}
{kind=link}

| W: | H:
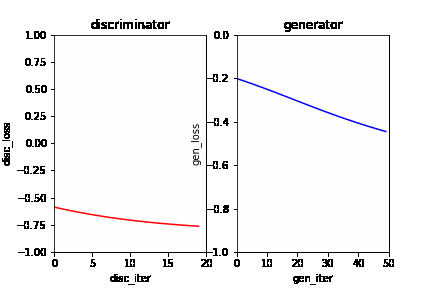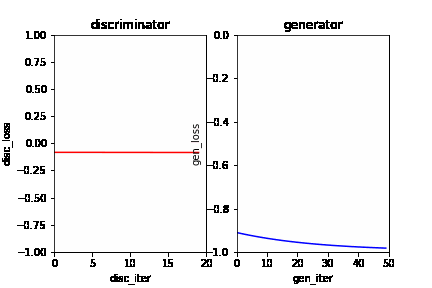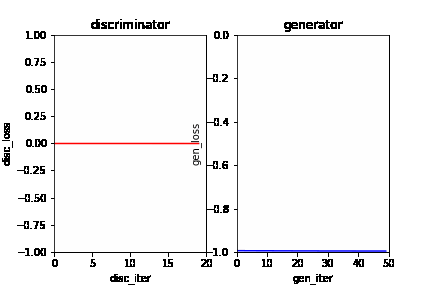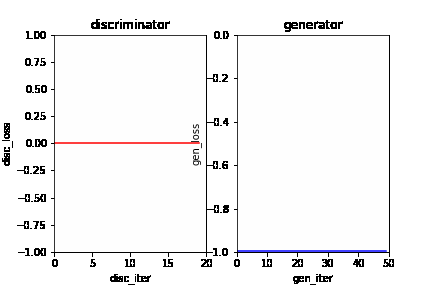
| W: | H: