Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
dcd5698d
S
Serving
项目概览
PaddlePaddle
/
Serving
9 个月 前同步成功
通知
183
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
dcd5698d
编写于
4月 19, 2022
作者:
T
TeslaZhao
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update doc
上级
02d581bb
变更
13
隐藏空白更改
内联
并排
Showing
13 changed file
with
770 addition
and
80 deletion
+770
-80
doc/Offical_Docs/7-0_Python_Pipeline_Int_CN.md
doc/Offical_Docs/7-0_Python_Pipeline_Int_CN.md
+1
-1
doc/Offical_Docs/7-1_Python_Pipeline_Design_CN.md
doc/Offical_Docs/7-1_Python_Pipeline_Design_CN.md
+35
-3
doc/Offical_Docs/7-2_Python_Pipeline_Senior_CN.md
doc/Offical_Docs/7-2_Python_Pipeline_Senior_CN.md
+310
-76
doc/images/low_precision_profile.png
doc/images/low_precision_profile.png
+0
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/README.md
examples/Pipeline/LowPrecision/ResNet50_Slim/README.md
+20
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/README_CN.md
examples/Pipeline/LowPrecision/ResNet50_Slim/README_CN.md
+20
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/benchmark.py
examples/Pipeline/LowPrecision/ResNet50_Slim/benchmark.py
+153
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/benchmark.sh
examples/Pipeline/LowPrecision/ResNet50_Slim/benchmark.sh
+44
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/config.yml
examples/Pipeline/LowPrecision/ResNet50_Slim/config.yml
+44
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/daisy.jpg
examples/Pipeline/LowPrecision/ResNet50_Slim/daisy.jpg
+0
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/pipeline_http_client.py
...peline/LowPrecision/ResNet50_Slim/pipeline_http_client.py
+35
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/pipeline_rpc_client.py
...ipeline/LowPrecision/ResNet50_Slim/pipeline_rpc_client.py
+37
-0
examples/Pipeline/LowPrecision/ResNet50_Slim/resnet50_web_service.py
...peline/LowPrecision/ResNet50_Slim/resnet50_web_service.py
+71
-0
未找到文件。
doc/Offical_Docs/7-0_Python_Pipeline_Int_CN.md
浏览文件 @
dcd5698d
...
@@ -6,7 +6,7 @@ Paddle Serving 实现了一套通用的多模型组合服务编程框架 Python
...
@@ -6,7 +6,7 @@ Paddle Serving 实现了一套通用的多模型组合服务编程框架 Python
Python Pipeline 使用案例请阅读
[
Python Pipeline 快速部署案例
](
./3-2_QuickStart_Pipeline_OCR_CN.md
)
Python Pipeline 使用案例请阅读
[
Python Pipeline 快速部署案例
](
./3-2_QuickStart_Pipeline_OCR_CN.md
)
通过阅读以下内容掌握 Python Pipeline
设计方案、高阶用法和
优化指南等。
通过阅读以下内容掌握 Python Pipeline
核心功能和使用方法、高阶功能用法和性能
优化指南等。
-
[
Python Pipeline 框架设计
](
7-1_Python_Pipeline_Design_CN.md
)
-
[
Python Pipeline 框架设计
](
7-1_Python_Pipeline_Design_CN.md
)
-
[
Python Pipeline 高阶用法
](
7-2_Python_Pipeline_Senior_CN.md
)
-
[
Python Pipeline 高阶用法
](
7-2_Python_Pipeline_Senior_CN.md
)
-
[
Python Pipeline 优化指南
](
7-3_Python_Pipeline_Optimize_CN.md
)
-
[
Python Pipeline 优化指南
](
7-3_Python_Pipeline_Optimize_CN.md
)
doc/Offical_Docs/7-1_Python_Pipeline_Design_CN.md
浏览文件 @
dcd5698d
...
@@ -42,7 +42,7 @@ Request 是输入结构,`key` 与 `value` 是配对的 string 数组。 `name`
...
@@ -42,7 +42,7 @@ Request 是输入结构,`key` 与 `value` 是配对的 string 数组。 `name`
Response 是输出结构,
`err_no`
和
`err_msg`
表达处理结果的正确性和错误信息,
`key`
和
`value`
为结果。
Response 是输出结构,
`err_no`
和
`err_msg`
表达处理结果的正确性和错误信息,
`key`
和
`value`
为结果。
Pipeline 服务包装了继承于 WebService 类,以
OCR 示例
为例,派生出 OcrService 类,get_pipeline_response 函数内实现 DAG 拓扑关系,默认服务入口为 read_op,函数返回的 Op 为最后一个处理,此处要求最后返回的 Op 必须唯一。
Pipeline 服务包装了继承于 WebService 类,以
[
OCR 示例
](
https://github.com/PaddlePaddle/Serving/tree/develop/examples/Pipeline/PaddleOCR/ocr
)
为例,派生出 OcrService 类,get_pipeline_response 函数内实现 DAG 拓扑关系,默认服务入口为 read_op,函数返回的 Op 为最后一个处理,此处要求最后返回的 Op 必须唯一。
所有服务和模型的所有配置信息在
`config.yml`
中记录,URL 的 name 字段由 OcrService 初始化定义;run_service 函数启动服务。
所有服务和模型的所有配置信息在
`config.yml`
中记录,URL 的 name 字段由 OcrService 初始化定义;run_service 函数启动服务。
...
@@ -177,6 +177,8 @@ Pipeline 的日志模块在 `logger.py` 中定义,使用了 `logging.handlers.
...
@@ -177,6 +177,8 @@ Pipeline 的日志模块在 `logger.py` 中定义,使用了 `logging.handlers.
```
```
**四. 服务超时与重试**
## 自定义信息
## 自定义信息
...
@@ -297,7 +299,6 @@ def init_op(self):
...
@@ -297,7 +299,6 @@ def init_op(self):
```
```
RequestOp 和 ResponseOp 是 Python Pipeline 的中2个特殊 Op,分别是用分解 RPC 数据加入到图执行引擎中,和拿到图执行引擎的预测结果并打包 RPC 数据到客户端。
RequestOp 和 ResponseOp 是 Python Pipeline 的中2个特殊 Op,分别是用分解 RPC 数据加入到图执行引擎中,和拿到图执行引擎的预测结果并打包 RPC 数据到客户端。
RequestOp 类的设计如下所示,核心是在 unpack_request_package 函数中解析请求数据,因此,当修改 Request 结构后重写此函数实现全新的解包处理。
RequestOp 类的设计如下所示,核心是在 unpack_request_package 函数中解析请求数据,因此,当修改 Request 结构后重写此函数实现全新的解包处理。
| 接口 | 说明 |
| 接口 | 说明 |
...
@@ -334,7 +335,6 @@ class RequestOp(Op):
...
@@ -334,7 +335,6 @@ class RequestOp(Op):
return
dict_data
,
log_id
,
None
,
""
return
dict_data
,
log_id
,
None
,
""
```
```
ResponseOp 类的设计如下所示,核心是在 pack_response_package 中打包返回结构,因此修改 Response 结构后重写此函数实现全新的打包格式。
ResponseOp 类的设计如下所示,核心是在 pack_response_package 中打包返回结构,因此修改 Response 结构后重写此函数实现全新的打包格式。
| 接口 | 说明 |
| 接口 | 说明 |
...
@@ -381,3 +381,35 @@ class ProductErrCode(enum.Enum):
...
@@ -381,3 +381,35 @@ class ProductErrCode(enum.Enum):
"""
"""
pass
pass
```
```
其使用方法如下所示,定义了一种错误类型
`Product_Error`
,在
`preprocess`
函数返回值中设置错误信息,在
`postprocess`
函数中也可以设置。
```
python
class
ProductErrCode
(
enum
.
Enum
):
"""
ProductErrCode is a base class for recording business error code.
product developers inherit this class and extend more error codes.
"""
Product_Error
=
100001
,
def
preprocess
(
self
,
input_dicts
,
data_id
,
log_id
):
"""
In preprocess stage, assembling data for process stage. users can
override this function for model feed features.
Args:
input_dicts: input data to be preprocessed
data_id: inner unique id
log_id: global unique id for RTT
Return:
input_dict: data for process stage
is_skip_process: skip process stage or not, False default
prod_errcode: None default, otherwise, product errores occured.
It is handled in the same way as exception.
prod_errinfo: "" default
"""
(
_
,
input_dict
),
=
input_dicts
.
items
()
if
input_dict
.
get_key
(
"product_error"
):
return
input_dict
,
False
,
Product_Error
,
"Product Error Occured"
return
input_dict
,
False
,
None
,
""
```
doc/Offical_Docs/7-2_Python_Pipeline_Senior_CN.md
浏览文件 @
dcd5698d
...
@@ -10,113 +10,347 @@
...
@@ -10,113 +10,347 @@
-
MKLDNN 推理加速
-
MKLDNN 推理加速
**一.
DAG 结构跳过某个 Op 运行
**
**一.
DAG 结构跳过某个 Op 运行
**
此应用场景一般在 Op 前后处理中有 if 条件判断时,不满足条件时,跳过后面处理。实际做法是在跳过此 Op 的 process 阶段,只要在 preprocess 做好判断,跳过 process 阶段,在和 postprocess 后直接返回即可。
此应用场景一般在 Op 前后处理中有 if 条件判断时,不满足条件时,跳过后面处理。实际做法是在跳过此 Op 的 process 阶段,只要在 preprocess 做好判断,跳过 process 阶段,在和 postprocess 后直接返回即可。
preprocess 返回结果列表的第二个结果是
`is_skip_process=True`
表示是否跳过当前 Op 的 process 阶段,直接进入 postprocess 处理。
preprocess 返回结果列表的第二个结果是
`is_skip_process=True`
表示是否跳过当前 Op 的 process 阶段,直接进入 postprocess 处理。
```
python
```
python
## Op::preprocess() 函数实现
def
preprocess
(
self
,
input_dicts
,
data_id
,
log_id
):
def
preprocess
(
self
,
input_dicts
,
data_id
,
log_id
):
"""
"""
In preprocess stage, assembling data for process stage. users can
In preprocess stage, assembling data for process stage. users can
override this function for model feed features.
override this function for model feed features.
Args:
Args:
input_dicts: input data to be preprocessed
input_dicts: input data to be preprocessed
data_id: inner unique id
data_id: inner unique id
log_id: global unique id for RTT
log_id: global unique id for RTT
Return:
Return:
input_dict: data for process stage
input_dict: data for process stage
is_skip_process: skip process stage or not, False default
is_skip_process: skip process stage or not, False default
prod_errcode: None default, otherwise, product errores occured.
prod_errcode: None default, otherwise, product errores occured.
It is handled in the same way as exception.
It is handled in the same way as exception.
prod_errinfo: "" default
prod_errinfo: "" default
"""
"""
# multiple previous Op
# multiple previous Op
if
len
(
input_dicts
)
!=
1
:
if
len
(
input_dicts
)
!=
1
:
_LOGGER
.
critical
(
_LOGGER
.
critical
(
self
.
_log
(
self
.
_log
(
"Failed to run preprocess: this Op has multiple previous "
"Failed to run preprocess: this Op has multiple previous "
"inputs. Please override this func."
))
"inputs. Please override this func."
))
os
.
_exit
(
-
1
)
os
.
_exit
(
-
1
)
(
_
,
input_dict
),
=
input_dicts
.
items
()
(
_
,
input_dict
),
=
input_dicts
.
items
()
return
input_dict
,
False
,
None
,
""
return
input_dict
,
False
,
None
,
""
```
```
以下示例 Jump::preprocess() 重载了原函数,返回了 True 字段
```
python
class
JumpOp
(
Op
):
## Overload func JumpOp::preprocess
def
preprocess
(
self
,
input_dicts
,
data_id
,
log_id
):
(
_
,
input_dict
),
=
input_dicts
.
items
()
if
input_dict
.
has_key
(
"jump"
):
return
input_dict
,
True
,
None
,
""
else
return
input_dict
,
False
,
None
,
""
```
**
二. 批量推理
**
**
二. 批量推理
**
Pipeline 支持批量推理,通过增大 batch size 可以提高 GPU 利用率。Python Pipeline 支持3种 batch 形式以及适用的场景如下:
Pipeline 支持批量推理,通过增大 batch size 可以提高 GPU 利用率。Python Pipeline 支持3种 batch 形式以及适用的场景如下:
-
场景1:一个推理请求包含批量数据(batch)
-
场景1:客户端打包批量数据(Client Batch)
-
单条数据定长,批量变长,数据转成BCHW格式
-
场景2:服务端合并多个请求动态合并批量(Server auto-batching)
-
单条数据变长,前处理中将单条数据做 padding 转成定长
-
场景3:服务端拆分一个批量数据推理请求成为多个小块推理(Server mini-batch)
-
场景2:一个推理请求的批量数据拆分成多个小块推理(mini-batch)
-
由于 padding 会按最长对齐,当一批数据中有个"极大"尺寸数据时会导致推理变慢
-
指定一个块大小,从而缩小"极大"尺寸数据的作用范围
1.
客户端打包批量数据
-
场景3:合并多个请求数据批量推理(auto-batching)
-
推理耗时明显长于前后处理,合并多个请求数据推理一次会提高吞吐和GPU利用率
当输入数据是 numpy 类型,如shape 为[4, 3, 512, 512]的 numpy 数据,即4张图片,可直接作为输入数据。
-
要求多个请求数据的 shape 一致
当输入数据的 shape 不同时,需要按最大的shape的尺寸 Padding 对齐后发送给服务端
2.
服务端合并多个请求动态合并批量
有助于提升吞吐和计算资源的利用率,当多个请求的 shape 尺寸不相同时,不支持合并。当前有2种合并策略,分别是:
-
等待时间与最大批量结合(推荐):结合
`batch_size`
和
`auto_batching_timeout`
配合使用,实际请求的批量条数超过
`batch_size`
时会立即执行,不超过时会等待
`auto_batching_timeout`
时间再执行
```
op:
bow:
# 并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 1
# client连接类型,brpc, grpc和local_predictor
client_type: brpc
# Serving IPs
server_endpoints: ["127.0.0.1:9393"]
# bow模型client端配置
client_config: "imdb_bow_client_conf/serving_client_conf.prototxt"
# 批量查询Serving的数量, 默认1。batch_size>1要设置auto_batching_timeout,否则不足batch_size时会阻塞
batch_size: 2
# 批量查询超时,与batch_size配合使用
auto_batching_timeout: 2000
```
-
阻塞式等待:仅设置
`batch_size`
,不设置
`auto_batching_timeout`
或
`auto_batching_timeout=0`
,会一直等待接受
`batch_size`
个请求后再推理。
```
op:
bow:
# 并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 1
# client连接类型,brpc, grpc和local_predictor
client_type: brpc
# Serving IPs
server_endpoints: ["127.0.0.1:9393"]
| 接口 | 说明 |
# bow模型client端配置
| :------------------------------------------: | :-----------------------------------------: |
client_config: "imdb_bow_client_conf/serving_client_conf.prototxt"
| batch | client 发送批量数据,client.predict 的 batch=True |
| mini-batch | preprocess 按 list 类型返回,参考 OCR 示例 RecOp的preprocess|
| auto-batching | config.yml 中 Op 级别设置 batch_size 和 auto_batching_timeout |
# 批量查询Serving的数量, 默认1。batch_size>1要设置auto_batching_timeout,否则不足batch_size时会阻塞
batch_size: 2
# 批量查询超时,与batch_size配合使用
auto_batching_timeout: 2000
```
** 三. 单机多卡推理 **
单机多卡推理,M 个 Op 进程与 N 个 GPU 卡绑定,在
`config.yml`
中配置3个参数有关系,首先选择进程模式、并发数即进程数,devices 是 GPU 卡 ID。绑定方法是进程启动时遍历 GPU 卡 ID,例如启动7个 Op 进程
`config.yml`
设置 devices:0,1,2,那么第1,4,7个启动的进程与0卡绑定,第2,4个启动的进程与1卡绑定,3,6进程与卡2绑定。
-
进程ID: 0 绑定 GPU 卡0
-
进程ID: 1 绑定 GPU 卡1
-
进程ID: 2 绑定 GPU 卡2
-
进程ID: 3 绑定 GPU 卡0
-
进程ID: 4 绑定 GPU 卡1
-
进程ID: 5 绑定 GPU 卡2
-
进程ID: 6 绑定 GPU 卡0
`config.yml`
中硬件配置:
3.
服务端拆分一个批量数据推理请求成为多个小块推理:会降低批量数据 Padding 对齐的大小,从而提升速度。可参考
[
OCR 示例
](
),核心思路是拆分数据成多个小批量,放入
list 对象 feed_list 并返回
```
```
#计算硬件 ID,当 devices 为""或不写时为 CPU 预测;当 devices 为"0", "0,1,2"时为 GPU 预测,表示使用的 GPU 卡
def preprocess(self, input_dicts, data_id, log_id):
devices: "0,1,2"
(_, input_dict), = input_dicts.items()
raw_im = input_dict["image"]
data = np.frombuffer(raw_im, np.uint8)
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
dt_boxes = input_dict["dt_boxes"]
dt_boxes = self.sorted_boxes(dt_boxes)
feed_list = []
img_list = []
max_wh_ratio = 0
## Many mini-batchs, the type of feed_data is list.
max_batch_size = len(dt_boxes)
# If max_batch_size is 0, skipping predict stage
if max_batch_size == 0:
return {}, True, None, ""
boxes_size = len(dt_boxes)
batch_size = boxes_size // max_batch_size
rem = boxes_size % max_batch_size
for bt_idx in range(0, batch_size + 1):
imgs = None
boxes_num_in_one_batch = 0
if bt_idx == batch_size:
if rem == 0:
continue
else:
boxes_num_in_one_batch = rem
elif bt_idx < batch_size:
boxes_num_in_one_batch = max_batch_size
else:
_LOGGER.error("batch_size error, bt_idx={}, batch_size={}".
format(bt_idx, batch_size))
break
start = bt_idx * max_batch_size
end = start + boxes_num_in_one_batch
img_list = []
for box_idx in range(start, end):
boximg = self.get_rotate_crop_image(im, dt_boxes[box_idx])
img_list.append(boximg)
h, w = boximg.shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
_, w, h = self.ocr_reader.resize_norm_img(img_list[0],
max_wh_ratio).shape
imgs = np.zeros((boxes_num_in_one_batch, 3, w, h)).astype('float32')
for id, img in enumerate(img_list):
norm_img = self.ocr_reader.resize_norm_img(img, max_wh_ratio)
imgs[id] = norm_img
feed = {"x": imgs.copy()}
feed_list.append(feed)
return feed_list, False, None, ""
```
```
** 四. 多种计算芯片上推理 **
**三. 单机多卡推理**
单机多卡推理与
`config.yml`
中配置4个参数关系紧密,
`is_thread_op`
、
`concurrency`
、
`device_type`
和
`devices`
,必须在进程模型和 GPU 模式,每张卡上可分配多个进程,即 M 个 Op 进程与 N 个 GPU 卡绑定。
```
dag:
#op资源类型, True, 为线程模型;False,为进程模型
is_thread_op: False
op:
det:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 6
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
local_service_conf:
client_type: local_predictor
# device_type, 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
device_type: 0
# 计算硬件 ID,当 devices 为""或不写时为 CPU 预测;当 devices 为"0", "0,1,2"时为 GPU 预测,表示使用的 GPU 卡
devices: "0,1,2"
```
以上述案例为例,
`concurrency:6`
,即启动6个进程,
`devices:0,1,2`
,根据轮询分配机制,得到如下绑定关系:
-
进程ID: 0 绑定 GPU 卡0
-
进程ID: 1 绑定 GPU 卡1
-
进程ID: 2 绑定 GPU 卡2
-
进程ID: 3 绑定 GPU 卡0
-
进程ID: 4 绑定 GPU 卡1
-
进程ID: 5 绑定 GPU 卡2
-
进程ID: 6 绑定 GPU 卡0
对于更灵活的进程与 GPU 卡绑定方式,会持续开发。
Pipeline 除了支持 CPU、GPU 芯片推理之外,还支持在多种计算硬件推理部署。在
`config.yml`
中由
`device_type`
和
`devices`
。优先使用
`device_type`
指定类型,当空缺时根据
`devices`
判断。
`device_type`
描述如下:
**四. 多种计算芯片上推理**
除了支持 CPU、GPU 芯片推理之外,Python Pipeline 还支持在多种计算硬件上推理。根据
`config.yml`
中的
`device_type`
和
`devices`
来设置推理硬件和加速库如下:
-
CPU(Intel) : 0
-
CPU(Intel) : 0
-
GPU(
Jetson/海光
DCU) : 1
-
GPU(
GPU / Jetson / 海光
DCU) : 1
-
TensorRT : 2
-
TensorRT : 2
-
CPU(Arm) : 3
-
CPU(Arm) : 3
-
XPU : 4
-
XPU : 4
-
Ascend310 : 5
-
Ascend310 : 5
-
ascend910 : 6
-
ascend910 : 6
config.yml中硬件配置:
当不设置
`device_type`
时,根据
`devices`
来设置,即当
`device_type`
为 "" 或空缺时为 CPU 推理;当有设定如"0,1,2"时,为 GPU 推理,并指定 GPU 卡。
以使用 GPU 的编号为0和1号卡并开启 TensorRT 为例,TensorRT 要配合
`ir_optim`
一同开启,
`config.yml`
详细配置如下:
```
```
#计算硬件类型: 空缺时由devices决定(CPU/GPU),0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
# 计算硬件类型
device_type: 0
device_type: 2
# 计算硬件ID,优先由device_type决定硬件类型
devices: "0,1"
# 开启ir优化
ir_optim: True
#计算硬件ID,优先由device_type决定硬件类型。devices为""或空缺时为CPU预测;当为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices: "" # "0,1"
```
```
**
五. 低精度推理
**
**
五. 低精度推理
**
Pipeline Serving支持低精度推理,CPU、GPU和TensoRT支持的精度类型如下图所示:
Pipeline Serving支持低精度推理,CPU、GPU和TensoRT支持的精度类型如下图所示:
-
CPU
-
fp32(default)
-
fp16
低精度推理需要有量化模型,配合
`config.yml`
配置一起使用,以
[
低精度示例
](
)
为例
-
bf16(mkldnn)
-
GPU
1.
CPU 低精度推理配置
-
fp32(default)
-
fp16
通过设置,
`device_type`
和
`devices`
字段使用 CPU 推理,通过调整
`precision`
、
`thread_num`
和
`use_mkldnn`
参数选择低精度和性能调优。
-
int8
-
Tensor RT
```
-
fp32(default)
op:
-
fp16
imagenet:
-
int8
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 1
使用int8时,要开启use_calib: True
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
参考
[
simple_web_service
](
../../examples/Pipeline/simple_web_service
)
示例
local_service_conf:
#uci模型路径
model_config: serving_server/
#计算硬件类型: 空缺时由devices决定(CPU/GPU),0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
device_type: 0
#计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices: ""
#client类型,包括brpc, grpc和local_predictor.local_predictor不启动Serving服务,进程内预测
client_type: local_predictor
#Fetch结果列表,以client_config中fetch_var的alias_name为准
fetch_list: ["score"]
#精度,CPU 支持: "fp32"(default), "bf16"(mkldnn); 不支持: "int8"
precision: "bf16"
#CPU 算数计算线程数,默认4线程
thread_num: 10
#开启 MKLDNN
use_mkldnn: True
```
2.
GPU + TensorRT 低精度推理
通过设置,
`device_type`
和
`devices`
字段使用原生 GPU 或 TensorRT 推理,通过调整
`precision`
、
`ir_optim`
和
`use_calib`
参数选择低精度和性能调优,如开启 TensorRT,必须一同开启
`ir_optim`
,
`use_calib`
仅配合 int8 使用。
```
op:
imagenet:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 1
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
local_service_conf:
#uci模型路径
model_config: serving_server/
#计算硬件类型: 空缺时由devices决定(CPU/GPU),0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
device_type: 2
#计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices: "1" # "0,1"
#client类型,包括brpc, grpc和local_predictor.local_predictor不启动Serving服务,进程内预测
client_type: local_predictor
#Fetch结果列表,以client_config中fetch_var的alias_name为准
fetch_list: ["score"]
#精度,GPU 支持: "fp32"(default), "fp16", "int8"
precision: "int8"
#开启 TensorRT int8 calibration
use_calib: True
#开启 ir_optim
ir_optim: True
```
3.
性能测试
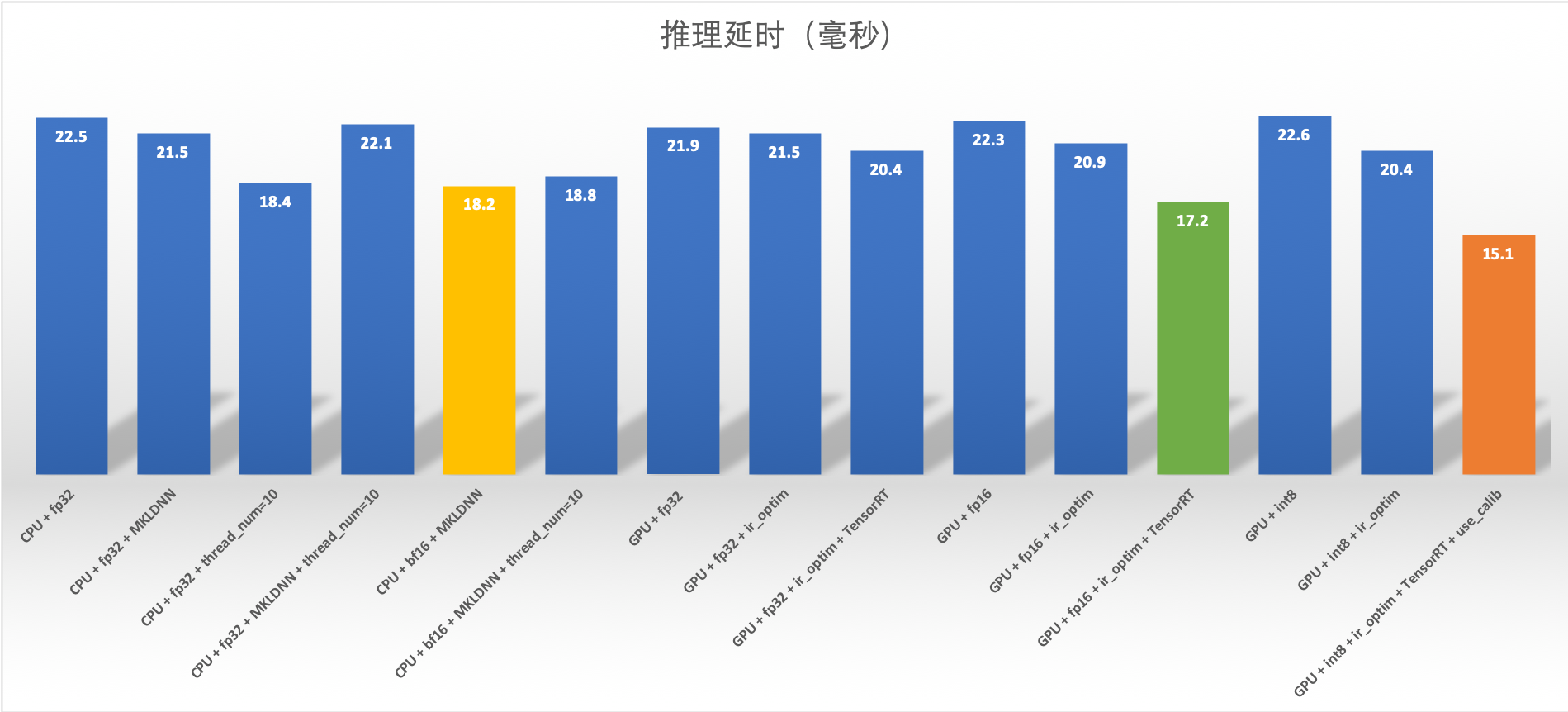
测试环境如下:
-
GPU 型号: A100-40GB
-
CPU 型号: Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
*
160
-
CUDA: CUDA Version: 11.2
-
CuDNN: 8.0
测试方法:
-
模型: Resnet50 量化模型
-
部署方法: Python Pipeline 部署
-
计时方法: 刨除第一次运行初始化,运行100次计算平均值
在此环境下测试不同精度推理结果,GPU 推理性能较好的配置是
-
GPU + int8 + ir_optim + TensorRT + use_calib : 15.1 ms
-
GPU + fp16 + ir_optim + TensorRT : 17.2 ms
CPU 推理性能较好的配置是
-
CPU + bf16 + MKLDNN : 18.2 ms
-
CPU + fp32 + thread_num=10 : 18.4 ms
完整性能指标如下:
<div
align=
center
>
<img
src=
'../images/low_precision_profile.png'
height =
"600"
align=
"middle"
/>
</div
doc/images/low_precision_profile.png
0 → 100644
浏览文件 @
dcd5698d
674.8 KB
examples/Pipeline/LowPrecision/ResNet50_Slim/README.md
0 → 100644
浏览文件 @
dcd5698d
# Imagenet Pipeline WebService
This document will takes Imagenet service as an example to introduce how to use Pipeline WebService.
## Get model
```
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ResNet50_quant.tar.gz
tar zxvf ResNet50_quant.tar.gz
```
## Start server
```
python3 resnet50_web_service.py &>log.txt &
```
## RPC test
```
python3 pipeline_rpc_client.py
```
examples/Pipeline/LowPrecision/ResNet50_Slim/README_CN.md
0 → 100644
浏览文件 @
dcd5698d
# Imagenet Pipeline WebService
这里以 Imagenet 服务为例来介绍 Pipeline WebService 的使用。
## 获取模型
```
wget https://paddle-inference-dist.bj.bcebos.com/inference_demo/python/resnet50/ResNet50_quant.tar.gz
tar zxvf ResNet50_quant.tar.gz
```
## 启动服务
```
python3 resnet50_web_service.py &>log.txt &
```
## 测试
```
python3 pipeline_rpc_client.py
```
examples/Pipeline/LowPrecision/ResNet50_Slim/benchmark.py
0 → 100644
浏览文件 @
dcd5698d
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
sys
import
os
import
base64
import
yaml
import
requests
import
time
import
json
from
paddle_serving_server.pipeline
import
PipelineClient
import
numpy
as
np
from
paddle_serving_client.utils
import
MultiThreadRunner
from
paddle_serving_client.utils
import
benchmark_args
,
show_latency
def
parse_benchmark
(
filein
,
fileout
):
with
open
(
filein
,
"r"
)
as
fin
:
res
=
yaml
.
load
(
fin
,
yaml
.
FullLoader
)
del_list
=
[]
for
key
in
res
[
"DAG"
].
keys
():
if
"call"
in
key
:
del_list
.
append
(
key
)
for
key
in
del_list
:
del
res
[
"DAG"
][
key
]
with
open
(
fileout
,
"w"
)
as
fout
:
yaml
.
dump
(
res
,
fout
,
default_flow_style
=
False
)
def
gen_yml
(
device
,
gpu_id
):
fin
=
open
(
"config.yml"
,
"r"
)
config
=
yaml
.
load
(
fin
,
yaml
.
FullLoader
)
fin
.
close
()
config
[
"dag"
][
"tracer"
]
=
{
"interval_s"
:
10
}
if
device
==
"gpu"
:
config
[
"op"
][
"imagenet"
][
"local_service_conf"
][
"device_type"
]
=
1
config
[
"op"
][
"imagenet"
][
"local_service_conf"
][
"devices"
]
=
gpu_id
else
:
config
[
"op"
][
"imagenet"
][
"local_service_conf"
][
"device_type"
]
=
0
with
open
(
"config2.yml"
,
"w"
)
as
fout
:
yaml
.
dump
(
config
,
fout
,
default_flow_style
=
False
)
def
cv2_to_base64
(
image
):
return
base64
.
b64encode
(
image
).
decode
(
'utf8'
)
def
run_http
(
idx
,
batch_size
):
print
(
"start thread ({})"
.
format
(
idx
))
url
=
"http://127.0.0.1:18000/imagenet/prediction"
start
=
time
.
time
()
with
open
(
os
.
path
.
join
(
"."
,
"daisy.jpg"
),
'rb'
)
as
file
:
image_data1
=
file
.
read
()
image
=
cv2_to_base64
(
image_data1
)
keys
,
values
=
[],
[]
for
i
in
range
(
batch_size
):
keys
.
append
(
"image_{}"
.
format
(
i
))
values
.
append
(
image
)
data
=
{
"key"
:
keys
,
"value"
:
values
}
latency_list
=
[]
start_time
=
time
.
time
()
total_num
=
0
while
True
:
l_start
=
time
.
time
()
r
=
requests
.
post
(
url
=
url
,
data
=
json
.
dumps
(
data
))
print
(
r
.
json
())
l_end
=
time
.
time
()
latency_list
.
append
(
l_end
*
1000
-
l_start
*
1000
)
total_num
+=
1
if
time
.
time
()
-
start_time
>
20
:
break
end
=
time
.
time
()
return
[[
end
-
start
],
latency_list
,
[
total_num
]]
def
multithread_http
(
thread
,
batch_size
):
multi_thread_runner
=
MultiThreadRunner
()
start
=
time
.
time
()
result
=
multi_thread_runner
.
run
(
run_http
,
thread
,
batch_size
)
end
=
time
.
time
()
total_cost
=
end
-
start
avg_cost
=
0
total_number
=
0
for
i
in
range
(
thread
):
avg_cost
+=
result
[
0
][
i
]
total_number
+=
result
[
2
][
i
]
avg_cost
=
avg_cost
/
thread
print
(
"Total cost: {}s"
.
format
(
total_cost
))
print
(
"Each thread cost: {}s. "
.
format
(
avg_cost
))
print
(
"Total count: {}. "
.
format
(
total_number
))
print
(
"AVG QPS: {} samples/s"
.
format
(
batch_size
*
total_number
/
total_cost
))
show_latency
(
result
[
1
])
def
run_rpc
(
thread
,
batch_size
):
client
=
PipelineClient
()
client
.
connect
([
'127.0.0.1:18080'
])
start
=
time
.
time
()
test_img_dir
=
"imgs/"
for
img_file
in
os
.
listdir
(
test_img_dir
):
with
open
(
os
.
path
.
join
(
test_img_dir
,
img_file
),
'rb'
)
as
file
:
image_data
=
file
.
read
()
image
=
cv2_to_base64
(
image_data
)
start_time
=
time
.
time
()
while
True
:
ret
=
client
.
predict
(
feed_dict
=
{
"image"
:
image
},
fetch
=
[
"res"
])
if
time
.
time
()
-
start_time
>
10
:
break
end
=
time
.
time
()
return
[[
end
-
start
]]
def
multithread_rpc
(
thraed
,
batch_size
):
multi_thread_runner
=
MultiThreadRunner
()
result
=
multi_thread_runner
.
run
(
run_rpc
,
thread
,
batch_size
)
if
__name__
==
"__main__"
:
if
sys
.
argv
[
1
]
==
"yaml"
:
mode
=
sys
.
argv
[
2
]
# brpc/ local predictor
thread
=
int
(
sys
.
argv
[
3
])
device
=
sys
.
argv
[
4
]
if
device
==
"gpu"
:
gpu_id
=
sys
.
argv
[
5
]
else
:
gpu_id
=
None
gen_yml
(
device
,
gpu_id
)
elif
sys
.
argv
[
1
]
==
"run"
:
mode
=
sys
.
argv
[
2
]
# http/ rpc
thread
=
int
(
sys
.
argv
[
3
])
batch_size
=
int
(
sys
.
argv
[
4
])
if
mode
==
"http"
:
multithread_http
(
thread
,
batch_size
)
elif
mode
==
"rpc"
:
multithread_rpc
(
thread
,
batch_size
)
elif
sys
.
argv
[
1
]
==
"dump"
:
filein
=
sys
.
argv
[
2
]
fileout
=
sys
.
argv
[
3
]
parse_benchmark
(
filein
,
fileout
)
examples/Pipeline/LowPrecision/ResNet50_Slim/benchmark.sh
0 → 100644
浏览文件 @
dcd5698d
export
FLAGS_profile_pipeline
=
1
alias
python3
=
"python3.6"
modelname
=
"clas-ResNet_v2_50"
# HTTP
#ps -ef | grep web_service | awk '{print $2}' | xargs kill -9
sleep
3
# Create yaml,If you already have the config.yaml, ignore it.
#python3 benchmark.py yaml local_predictor 1 gpu
rm
-rf
profile_log_
$modelname
echo
"Starting HTTP Clients..."
# Start a client in each thread, tesing the case of multiple threads.
for
thread_num
in
1 2 4 8 12 16
do
for
batch_size
in
1
do
echo
"----
${
modelname
}
thread num:
${
thread_num
}
batch size:
${
batch_size
}
mode:http ----"
>>
profile_log_
$modelname
# Start one web service, If you start the service yourself, you can ignore it here.
#python3 web_service.py >web.log 2>&1 &
#sleep 3
# --id is the serial number of the GPU card, Must be the same as the gpu id used by the server.
nvidia-smi
--id
=
3
--query-gpu
=
memory.used
--format
=
csv
-lms
1000
>
gpu_use.log 2>&1 &
nvidia-smi
--id
=
3
--query-gpu
=
utilization.gpu
--format
=
csv
-lms
1000
>
gpu_utilization.log 2>&1 &
echo
"import psutil
\n
cpu_utilization=psutil.cpu_percent(1,False)
\n
print('CPU_UTILIZATION:', cpu_utilization)
\n
"
>
cpu_utilization.py
# Start http client
python3 benchmark.py run http
$thread_num
$batch_size
>
profile 2>&1
# Collect CPU metrics, Filter data that is zero momentarily, Record the maximum value of GPU memory and the average value of GPU utilization
python3 cpu_utilization.py
>>
profile_log_
$modelname
grep
-av
'^0 %'
gpu_utilization.log
>
gpu_utilization.log.tmp
awk
'BEGIN {max = 0} {if(NR>1){if ($modelname > max) max=$modelname}} END {print "MAX_GPU_MEMORY:", max}'
gpu_use.log
>>
profile_log_
$modelname
awk
-F
' '
'{sum+=$1} END {print "GPU_UTILIZATION:", sum/NR, sum, NR }'
gpu_utilization.log.tmp
>>
profile_log_
$modelname
# Show profiles
python3 ../../../util/show_profile.py profile
$thread_num
>>
profile_log_
$modelname
tail
-n
8 profile
>>
profile_log_
$modelname
echo
''
>>
profile_log_
$modelname
done
done
# Kill all nvidia-smi background task.
pkill nvidia-smi
examples/Pipeline/LowPrecision/ResNet50_Slim/config.yml
0 → 100644
浏览文件 @
dcd5698d
#worker_num, 最大并发数。当build_dag_each_worker=True时, 框架会创建worker_num个进程,每个进程内构建grpcSever和DAG
##当build_dag_each_worker=False时,框架会设置主线程grpc线程池的max_workers=worker_num
worker_num
:
1
#http端口, rpc_port和http_port不允许同时为空。当rpc_port可用且http_port为空时,不自动生成http_port
http_port
:
18080
rpc_port
:
9993
dag
:
#op资源类型, True, 为线程模型;False,为进程模型
is_thread_op
:
False
op
:
imagenet
:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency
:
1
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
local_service_conf
:
#uci模型路径
model_config
:
serving_server/
#计算硬件类型: 空缺时由devices决定(CPU/GPU),0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
device_type
:
1
#计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices
:
"
0"
# "0,1"
#client类型,包括brpc, grpc和local_predictor.local_predictor不启动Serving服务,进程内预测
client_type
:
local_predictor
#Fetch结果列表,以client_config中fetch_var的alias_name为准
fetch_list
:
[
"
score"
]
#precsion, 预测精度,降低预测精度可提升预测速度
#GPU 支持: "fp32"(default), "fp16", "int8";
#CPU 支持: "fp32"(default), "fp16", "bf16"(mkldnn); 不支持: "int8"
precision
:
"
fp32"
#开启 TensorRT calibration
use_calib
:
True
#开启 ir_optim
ir_optim
:
True
examples/Pipeline/LowPrecision/ResNet50_Slim/daisy.jpg
0 → 100644
浏览文件 @
dcd5698d
38.8 KB
examples/Pipeline/LowPrecision/ResNet50_Slim/pipeline_http_client.py
0 → 100644
浏览文件 @
dcd5698d
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
numpy
as
np
import
requests
import
json
import
cv2
import
base64
import
os
def
cv2_to_base64
(
image
):
return
base64
.
b64encode
(
image
).
decode
(
'utf8'
)
if
__name__
==
"__main__"
:
url
=
"http://127.0.0.1:18080/imagenet/prediction"
with
open
(
os
.
path
.
join
(
"."
,
"daisy.jpg"
),
'rb'
)
as
file
:
image_data1
=
file
.
read
()
image
=
cv2_to_base64
(
image_data1
)
data
=
{
"key"
:
[
"image"
],
"value"
:
[
image
]}
for
i
in
range
(
1
):
r
=
requests
.
post
(
url
=
url
,
data
=
json
.
dumps
(
data
))
print
(
r
.
json
())
examples/Pipeline/LowPrecision/ResNet50_Slim/pipeline_rpc_client.py
0 → 100644
浏览文件 @
dcd5698d
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
paddle_serving_server.pipeline
import
PipelineClient
import
numpy
as
np
import
requests
import
json
import
cv2
import
base64
import
os
client
=
PipelineClient
()
client
.
connect
([
'127.0.0.1:9993'
])
def
cv2_to_base64
(
image
):
return
base64
.
b64encode
(
image
).
decode
(
'utf8'
)
with
open
(
"daisy.jpg"
,
'rb'
)
as
file
:
image_data
=
file
.
read
()
image
=
cv2_to_base64
(
image_data
)
for
i
in
range
(
1
):
ret
=
client
.
predict
(
feed_dict
=
{
"image"
:
image
},
fetch
=
[
"label"
,
"prob"
])
print
(
ret
)
examples/Pipeline/LowPrecision/ResNet50_Slim/resnet50_web_service.py
0 → 100644
浏览文件 @
dcd5698d
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
sys
from
paddle_serving_app.reader
import
Sequential
,
URL2Image
,
Resize
,
CenterCrop
,
RGB2BGR
,
Transpose
,
Div
,
Normalize
,
Base64ToImage
from
paddle_serving_server.web_service
import
WebService
,
Op
import
logging
import
numpy
as
np
import
base64
,
cv2
class
ImagenetOp
(
Op
):
def
init_op
(
self
):
self
.
seq
=
Sequential
([
Resize
(
256
),
CenterCrop
(
224
),
RGB2BGR
(),
Transpose
((
2
,
0
,
1
)),
Div
(
255
),
Normalize
([
0.485
,
0.456
,
0.406
],
[
0.229
,
0.224
,
0.225
],
True
)
])
self
.
label_dict
=
{}
label_idx
=
0
with
open
(
"imagenet.label"
)
as
fin
:
for
line
in
fin
:
self
.
label_dict
[
label_idx
]
=
line
.
strip
()
label_idx
+=
1
def
preprocess
(
self
,
input_dicts
,
data_id
,
log_id
):
(
_
,
input_dict
),
=
input_dicts
.
items
()
batch_size
=
len
(
input_dict
.
keys
())
imgs
=
[]
for
key
in
input_dict
.
keys
():
data
=
base64
.
b64decode
(
input_dict
[
key
].
encode
(
'utf8'
))
data
=
np
.
fromstring
(
data
,
np
.
uint8
)
im
=
cv2
.
imdecode
(
data
,
cv2
.
IMREAD_COLOR
)
img
=
self
.
seq
(
im
)
imgs
.
append
(
img
[
np
.
newaxis
,
:].
copy
())
input_imgs
=
np
.
concatenate
(
imgs
,
axis
=
0
)
return
{
"image"
:
input_imgs
},
False
,
None
,
""
def
postprocess
(
self
,
input_dicts
,
fetch_dict
,
data_id
,
log_id
):
score_list
=
fetch_dict
[
"score"
]
result
=
{
"label"
:
[],
"prob"
:
[]}
for
score
in
score_list
:
score
=
score
.
tolist
()
max_score
=
max
(
score
)
result
[
"label"
].
append
(
self
.
label_dict
[
score
.
index
(
max_score
)]
.
strip
().
replace
(
","
,
""
))
result
[
"prob"
].
append
(
max_score
)
result
[
"label"
]
=
str
(
result
[
"label"
])
result
[
"prob"
]
=
str
(
result
[
"prob"
])
return
result
,
None
,
""
class
ImageService
(
WebService
):
def
get_pipeline_response
(
self
,
read_op
):
image_op
=
ImagenetOp
(
name
=
"imagenet"
,
input_ops
=
[
read_op
])
return
image_op
uci_service
=
ImageService
(
name
=
"imagenet"
)
uci_service
.
prepare_pipeline_config
(
"config.yml"
)
uci_service
.
run_service
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
