jvm 增加两篇实战
Showing
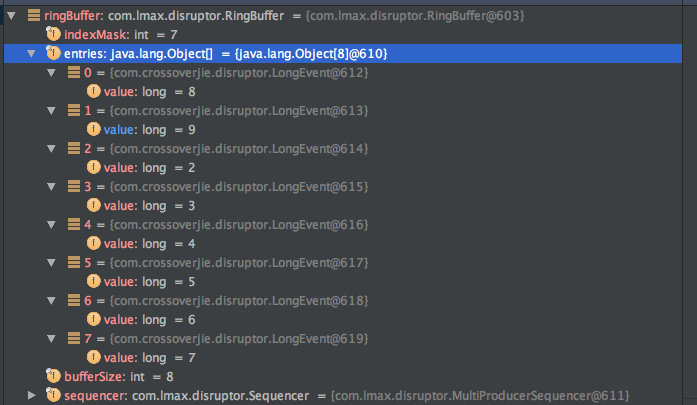
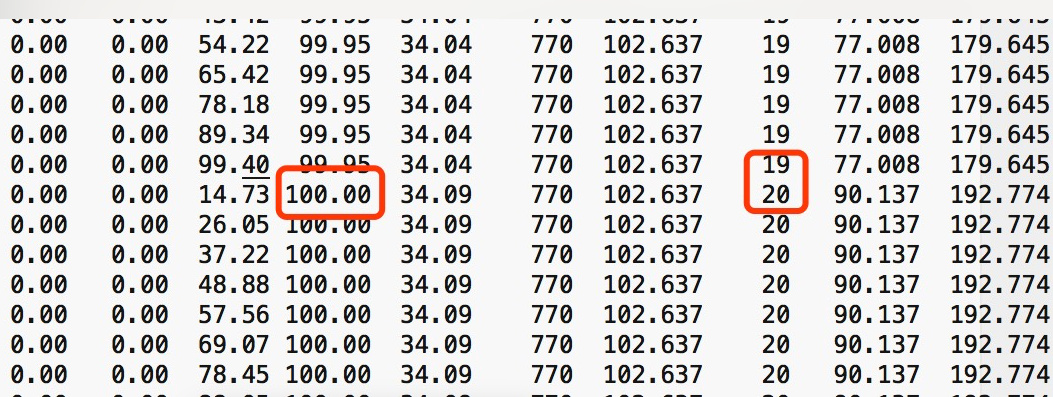
docs/jvm/cpu-percent-100.md
0 → 100644
docs/jvm/oom.md
0 → 100644
{kind=link}
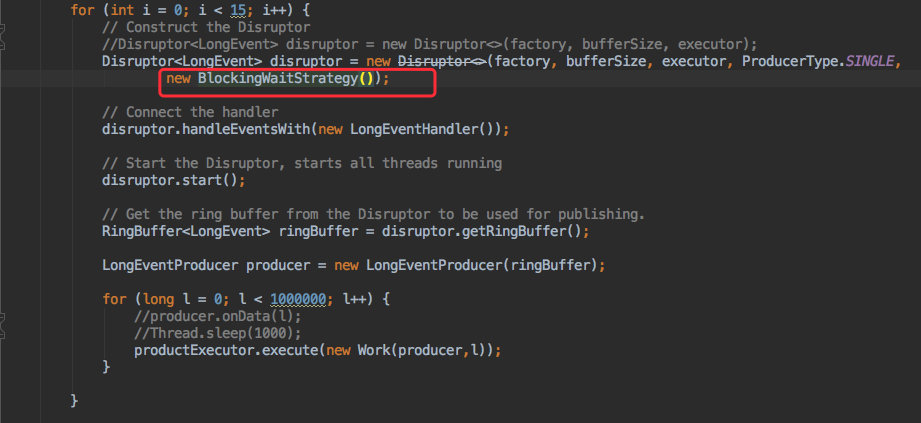
59.4 KB
{kind=link}

61.3 KB
{kind=link}
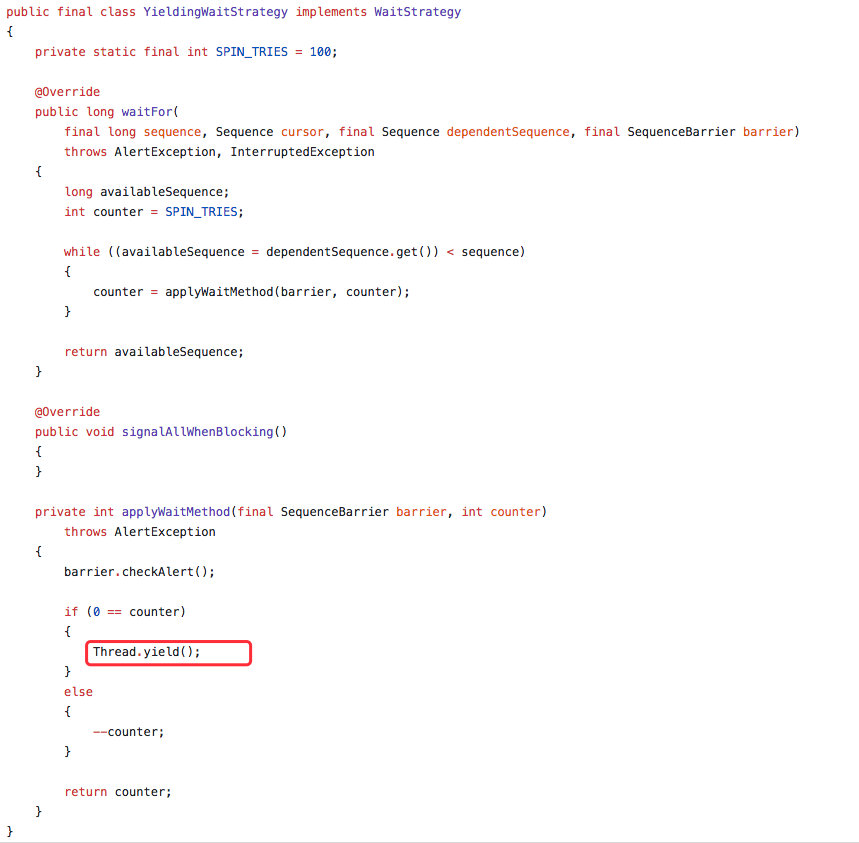
69.2 KB
{kind=link}
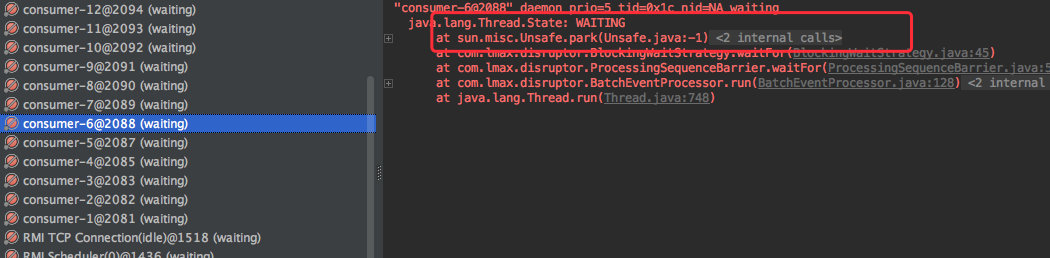
64.1 KB
{kind=link}
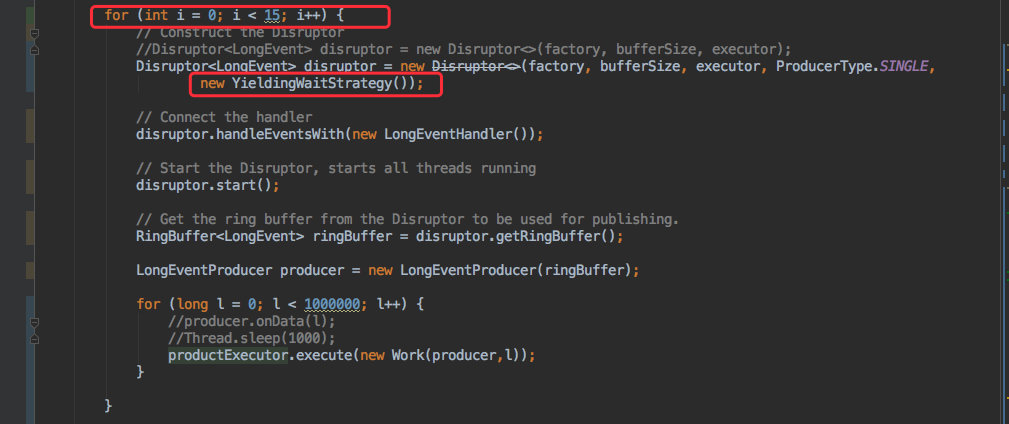
60.7 KB
{kind=link}
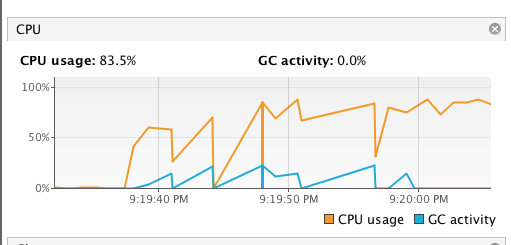
20.4 KB
{kind=link}
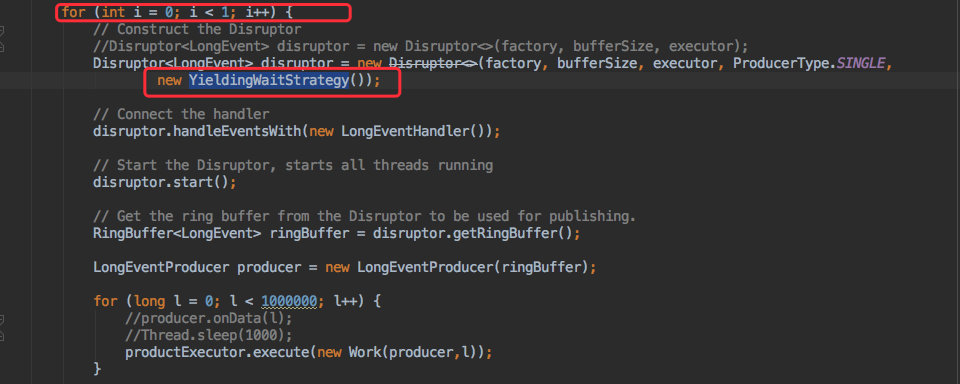
59.5 KB
{kind=link}
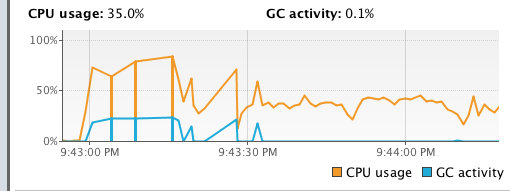
20.0 KB
{kind=link}
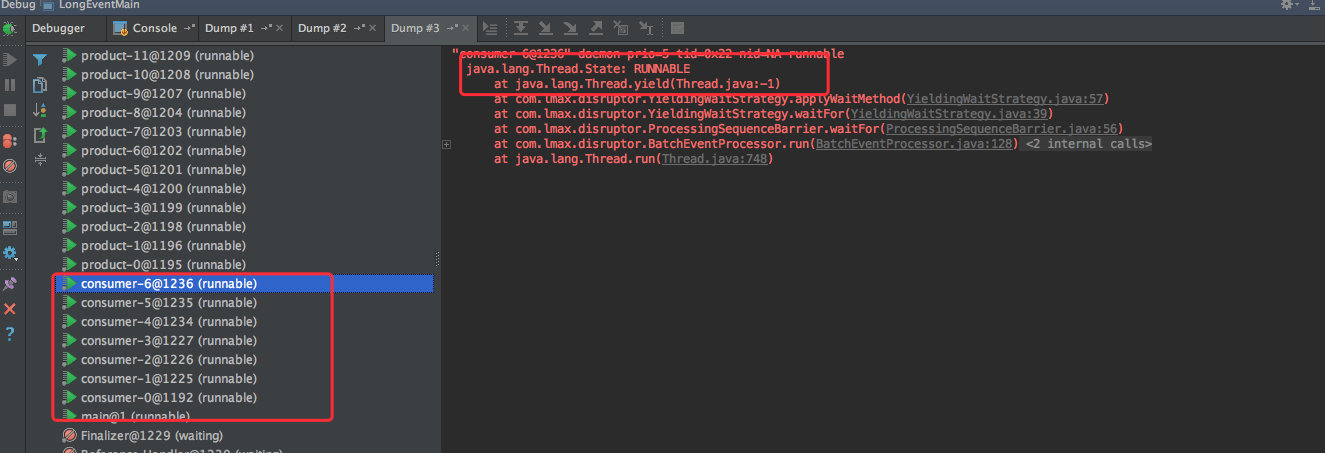
98.7 KB
{kind=link}

30.9 KB
{kind=link}
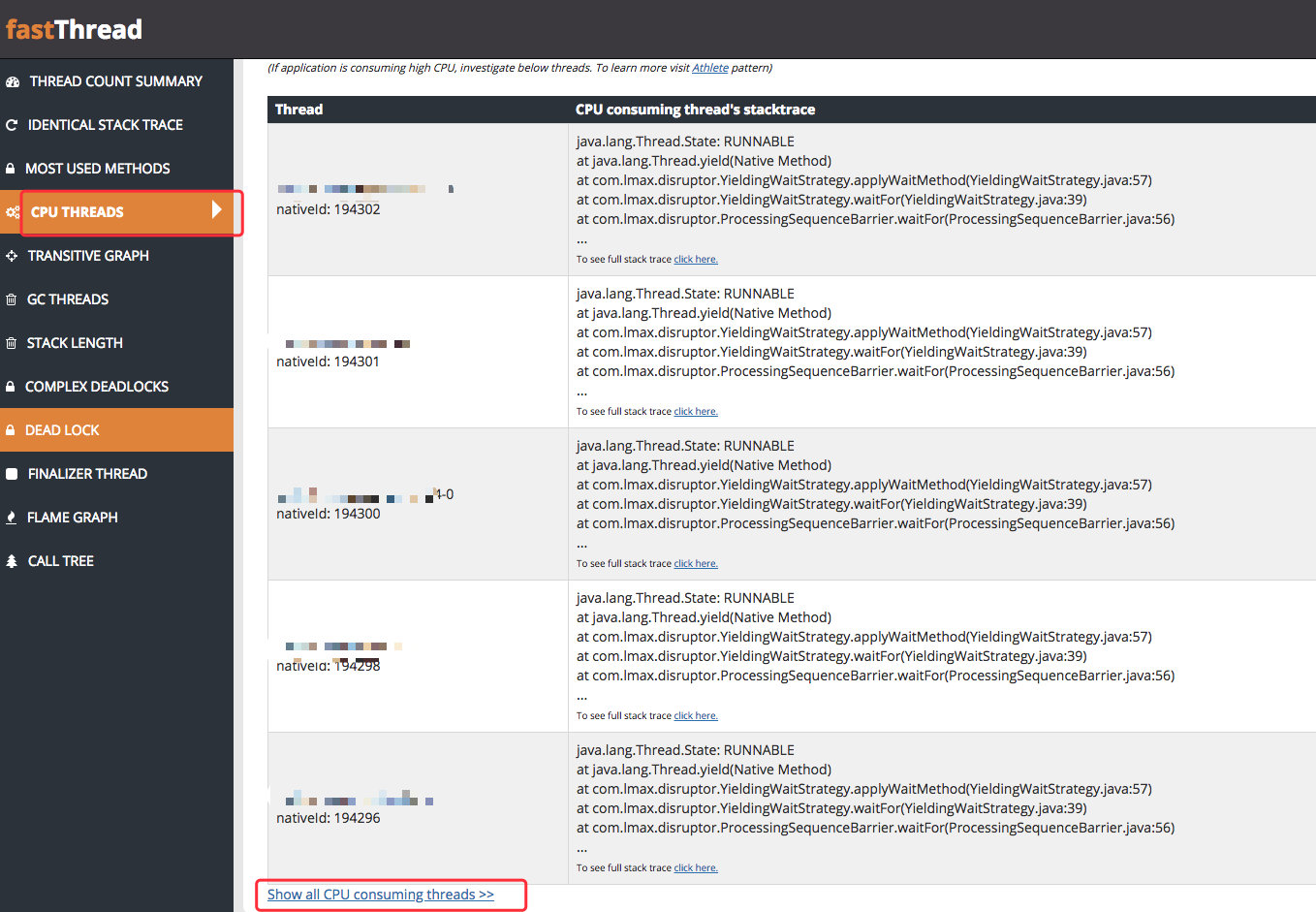
253.5 KB
{kind=link}

73.3 KB
{kind=link}
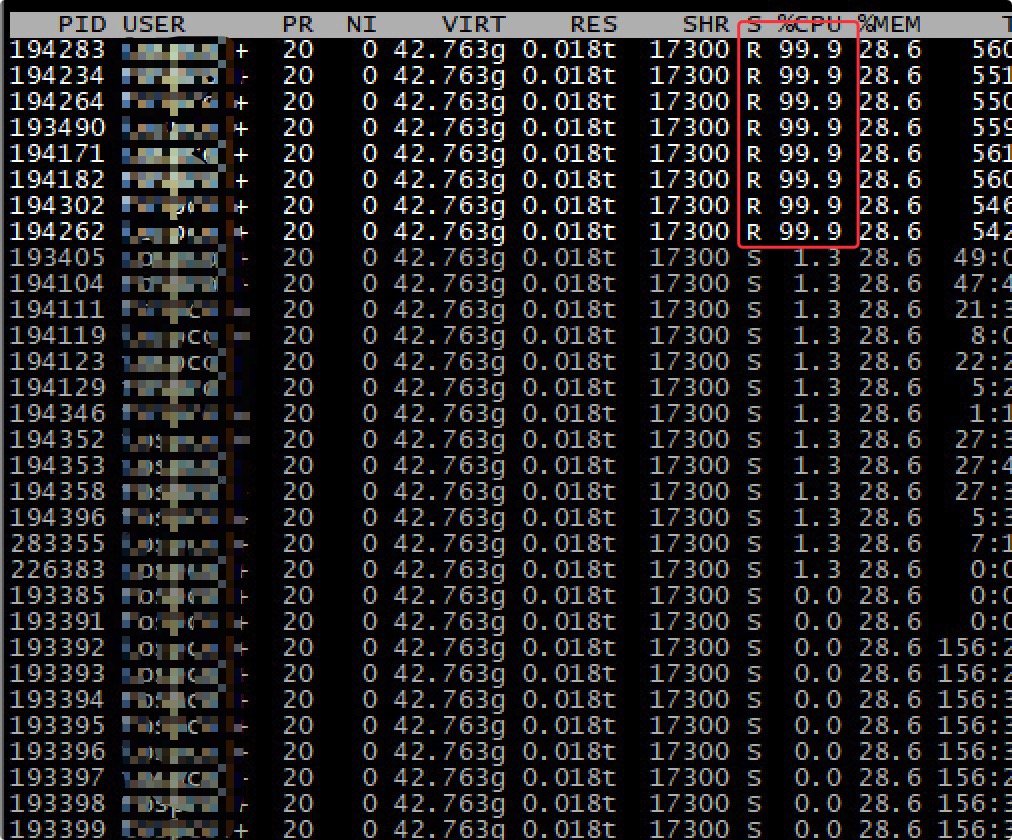
270.7 KB
{kind=link}

78.2 KB
{kind=link}
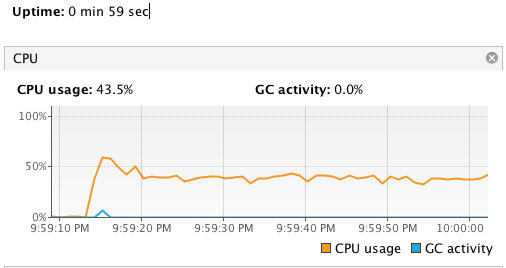
18.2 KB
{kind=link}
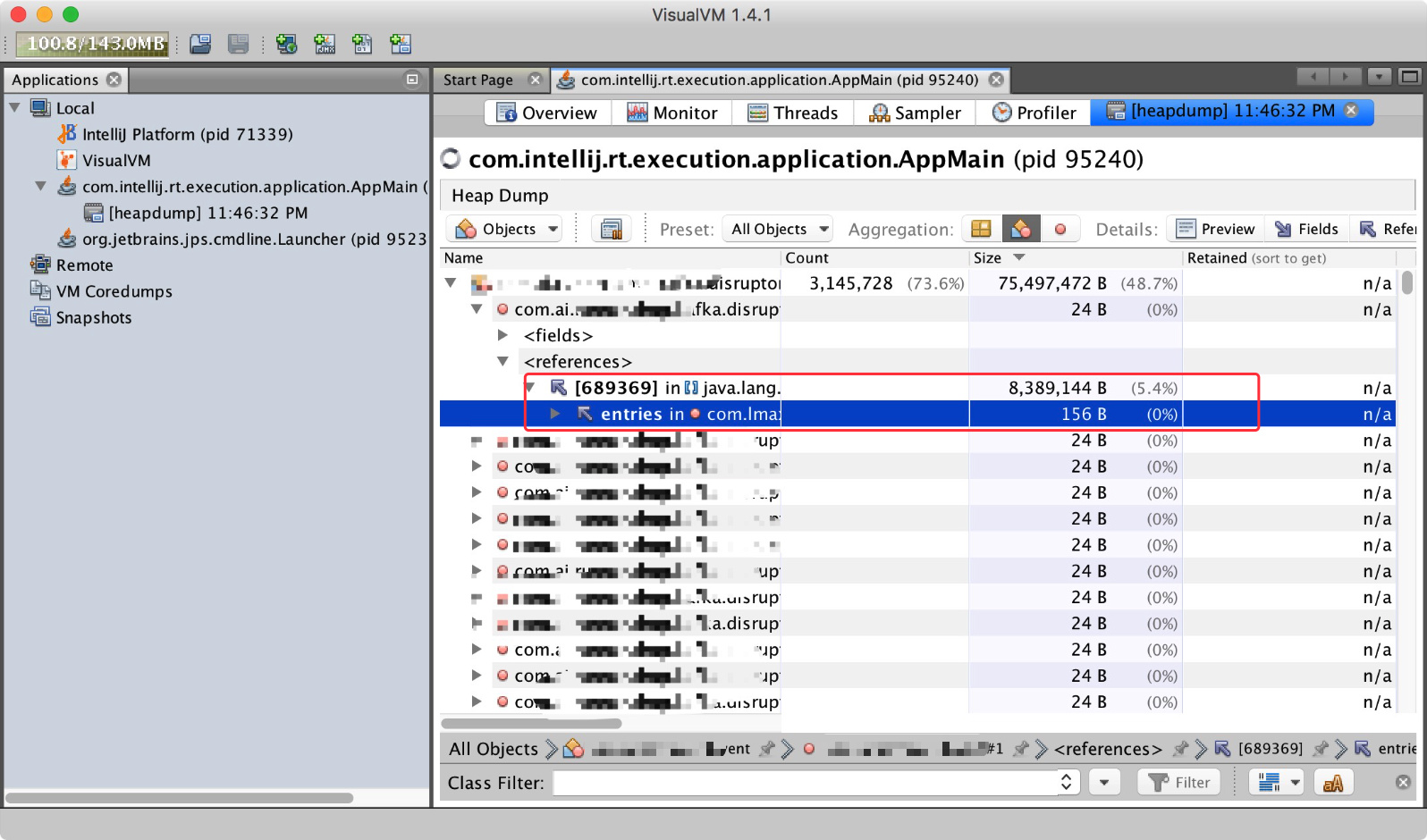
341.9 KB
{kind=link}
184.5 KB
{kind=link}
337.6 KB
{kind=link}
157.6 KB
{kind=link}
291.7 KB
{kind=link}
87.8 KB
{kind=link}
252.8 KB