泛型
Showing
docs/enum/enum.md
0 → 100644
docs/exception/shijian.md
0 → 100644
docs/generic/generic.md
0 → 100644
docs/generic/true-generic.md
0 → 100644
{kind=link}
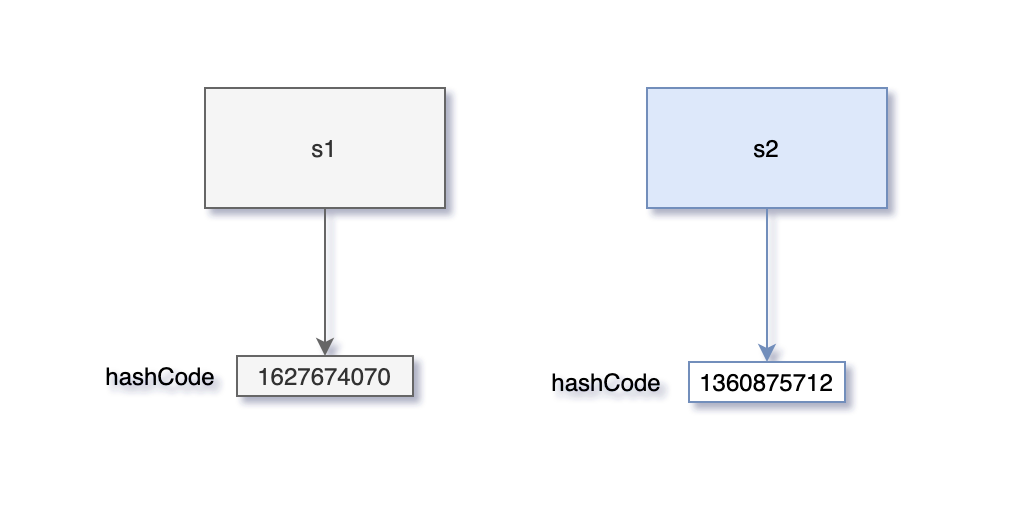
25.4 KB
{kind=link}
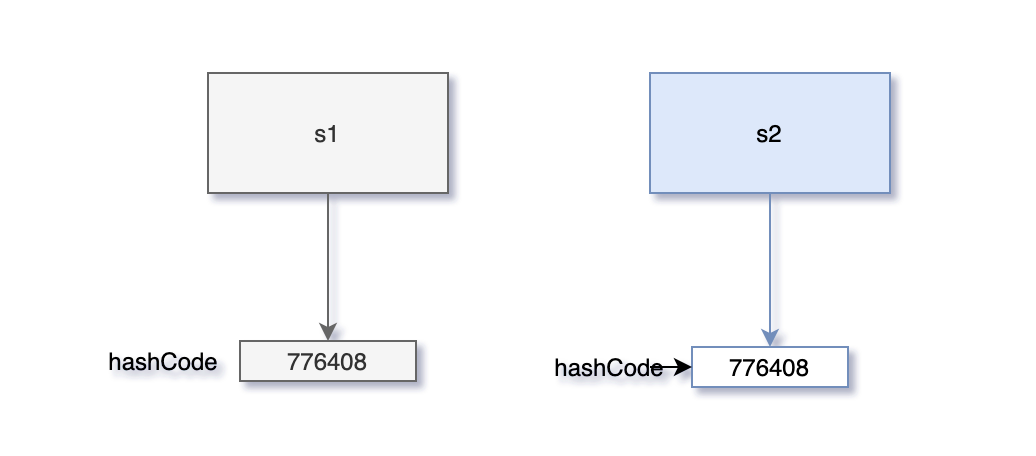
24.5 KB
images/enum/enum-01.png
0 → 100644
{kind=link}

17.8 KB
images/enum/enum-02.png
0 → 100644
{kind=link}
4.1 KB
images/enum/enum-03.png
0 → 100644
{kind=link}
4.1 KB
images/enum/enum-04.png
0 → 100644
{kind=link}
4.5 KB
images/generic/generic-01.png
0 → 100644
{kind=link}

48.9 KB
{kind=link}

45.4 KB
{kind=link}

360.7 KB
{kind=link}

246.8 KB
{kind=link}

32.6 KB