Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
qq_21481385
JavaGuide
提交
0ebf7cae
J
JavaGuide
项目概览
qq_21481385
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
0ebf7cae
编写于
6月 23, 2020
作者:
S
shuang.kou
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
feat:redis 常见问题部分重构
上级
e2494878
变更
7
隐藏空白更改
内联
并排
Showing
7 changed file
with
99 addition
and
35 deletion
+99
-35
README.md
README.md
+1
-1
docs/database/Redis/Redis.md
docs/database/Redis/Redis.md
+98
-34
docs/database/Redis/images/redis/redis-vs-memcached.png
docs/database/Redis/images/redis/redis-vs-memcached.png
+0
-0
docs/database/Redis/images/redis/what-is-redis.png
docs/database/Redis/images/redis/what-is-redis.png
+0
-0
docs/database/Redis/images/redis/使用缓存之后.png
docs/database/Redis/images/redis/使用缓存之后.png
+0
-0
docs/database/Redis/images/redis/单体架构.png
docs/database/Redis/images/redis/单体架构.png
+0
-0
docs/database/Redis/images/redis/集中式缓存架构.png
docs/database/Redis/images/redis/集中式缓存架构.png
+0
-0
未找到文件。
README.md
浏览文件 @
0ebf7cae
...
...
@@ -219,7 +219,7 @@
### Redis
*
[
Redis 常见问题总结
](
docs/database/Redis/
R
edis.md
)
*
[
Redis 常见问题总结
](
docs/database/Redis/
r
edis.md
)
*
**Redis 系列文章合集:**
1.
[
5种基本数据结构
](
docs/database/Redis/redis-collection/Redis(1
)
——5种基本数据结构.md)
2.
[
跳跃表
](
docs/database/Redis/redis-collection/Redis(2
)
——跳跃表.md)
...
...
docs/database/Redis/Redis.md
浏览文件 @
0ebf7cae
点击关注
[
公众号
](
#公众号
)
及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
### 目录
-
[
Redis 简介
](
#redis-简介
)
-
[
为什么要用 Redis/为什么要用缓存
](
#为什么要用-redis为什么要用缓存
)
-
[
为什么要用 Redis 而不用 map/guava 做缓存?
](
#为什么要用-redis-而不用-mapguava-做缓存
)
-
[
简单说说有哪些本地缓存解决方案?
](
#简单说说有哪些本地缓存解决方案
)
-
[
为什么要有分布式缓存?/为什么不直接用本地缓存?
](
#为什么要有分布式缓存为什么不直接用本地缓存
)
-
[
分布式缓存有哪些常见的技术选型方案呢?
](
#分布式缓存有哪些常见的技术选型方案呢
)
-
[
简单介绍一下 Redis 呗!
](
#简单介绍一下-redis-呗
)
-
[
说一下 Redis 和 Memcached 的区别和共同点
](
#说一下-redis-和-memcached-的区别和共同点
)
-
[
为什么要用 Redis/为什么要用缓存?
](
#为什么要用-redis为什么要用缓存
)
-
[
Redis 的线程模型
](
#redis-的线程模型
)
-
[
Redis 和 Memcached 的区别和共同点
](
#redis-和-memcached-的区别和共同点
)
-
[
Redis 常见数据结构以及使用场景分析
](
#redis-常见数据结构以及使用场景分析
)
-
[
1.String
](
#1string
)
-
[
2.Hash
](
#2hash
)
...
...
@@ -24,60 +24,86 @@
-
[
如何保证缓存与数据库双写时的数据一致性?
](
#如何保证缓存与数据库双写时的数据一致性
)
-
[
参考
](
#参考
)
### Redis 简介
*正式开始 Redis 之前,我们先来回顾一下在 Java 后端领域,有哪些可以用来当做缓存。*
简单来说 Redis 就是一个数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。另外,Redis 也经常用来做分布式锁。Redis 提供了多种数据类型来支持不同的业务场景。除此之外,Redis 支持事务 、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
### 简单说说有哪些本地缓存解决方案?
### 为什么要用 Redis/为什么要用缓存
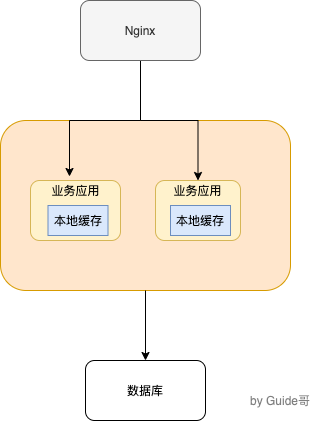
*先来聊聊本地缓存,这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。*
主要从“高性能”和“高并发”这两点来看待这个问题
。
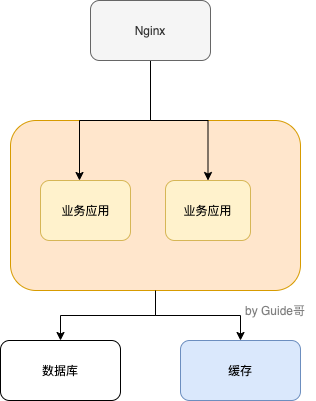
常见的单体架构图如下,我们使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库,并且使用的是本地缓存
。
**高性能:**

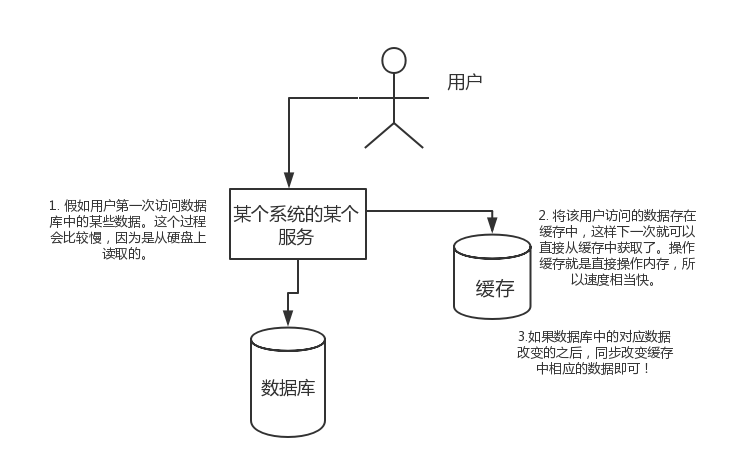
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
*那本地缓存的方案有哪些呢?且听 Guide 给你来说一说。*
**一:JDK 自带的 `HashMap` 和 `ConcurrentHashMap`了。**
**高并发:**
`ConcurrentHashMap`
可以看作是线程安全版本的
`HashMap`
,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:过期时间、淘汰机制、命中率统计这三点。
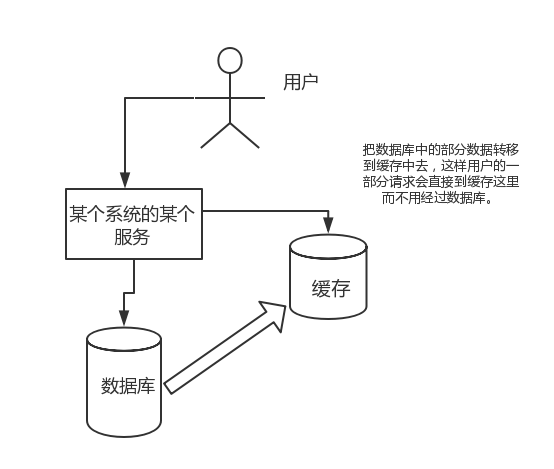
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
**二:`Ehcache` 、 `Guava Cache` 、`Spring Cache`这三者是使用的比较多的本地缓存框架。**
`Ehcache`
的话相比于其他两者更加重量。不过,相比于
`Guava Cache`
、
`Spring Cache`
来说,
`Ehcache`
支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。
### 为什么要用 Redis 而不用 map/guava 做缓存?
`Guava Cache`
和
`Spring Cache`
两者的话比较像。
> 下面的内容来自 segmentfault 一位网友的提问,地址:https://segmentfault.com/q/1010000009106416
`Guava`
相比于
`Spring Cache`
的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和
`ConcurrentHashMap`
的思想有异曲同工之妙。
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性
。
使用
`Spring Cache`
的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出
。
使用 Redis 或 Memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 Redis 或 Memcached 服务的高可用,整个程序架构上较为复杂。
**三 :`Caffeine`**
### Redis 的线程模型
相比于
`Guava`
来说
`Caffeine`
在各个方面比如性能要更加优秀,一般建议使用其来替代
`Guava`
。并且,
`Guava`
和
`Caffeine`
的使用方式很像!
> 参考地址:https://www.javazhiyin.com/22943.html
本地缓存固然好,但是缺陷也很明显,比如多个相同服务之间的本地缓存的数据无法共享。
Redis 内部使用文件事件处理器
`file event handler`
,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
*下面我们从为什么要有分布式缓存为接入点来正式进入 Redis 的相关问题总结。*
文件事件处理器的结构包含 4 个部分:
### 为什么要有分布式缓存?/为什么不直接用本地缓存?
-
多个 socket
-
IO 多路复用程序
-
文件事件分派器
-
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
*我们可以把分布式缓存(Distributed Cache) 看作是一种内存数据库的服务,它的最终作用就是提供缓存数据的服务。*
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
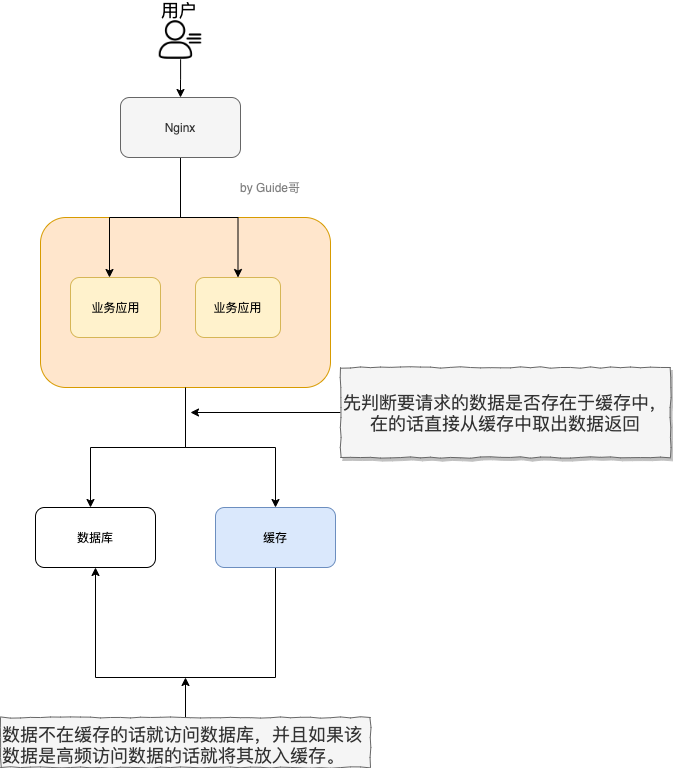
如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库和缓存。

本地的缓存的优势是低依赖,比较轻量并且通常相比于使用分布式缓存要更加简单。
再来分析一下本地缓存的局限性:
### Redis 和 Memcached 的区别和共同点
1.
本地缓存对分布式架构支持不友好,比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有。
2.
容量跟随服务器限制明显。
使用分布式缓存之后,缓存部署在一台单独的服务器上,即使同一个相同的服务部署在再多机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大。
使用分布式缓存的缺点呢,也很显而易见,那就是你需要为分布式缓存引入额外的服务比如 Redis 或 Memcached,你需要单独保证 Redis 或 Memcached 服务的高可用。
### 分布式缓存有哪些常见的技术选型方案呢?
分布式缓存的话,使用的比较多的主要是 Memcached 和 Redis。不过,现在基本没有看过还有项目使用 Memcached 来做缓存,都是直接用 Redis。
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
### 简单介绍一下 Redis 呗!
简单来说 Redis 就是一个 C 语言开发的数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
另外,除了做缓存之外,Redis 也经常用来做分布式锁,甚至是消息队列。
Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。
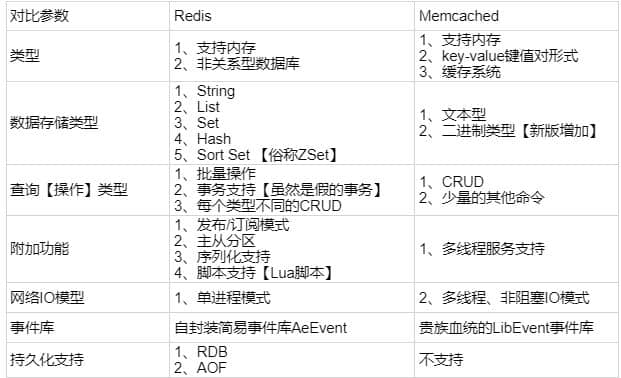
### 说一下 Redis 和 Memcached 的区别和共同点
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
**共同点
:**
**共同点
**
:
1.
都是基于内存的缓存。
2.
都有过期策略。
3.
两者的性能都非常高。
**区别
:**
**区别
**
:
1.
**Redis 支持更丰富的数据类型(支持更复杂的应用场景)**
。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
2.
**Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。**
...
...
@@ -85,10 +111,48 @@ Redis 内部使用文件事件处理器 `file event handler`,这个文件事
4.
**Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
5.
**Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的.**
6.
**Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。**
(Redis 6.0 引入了多线程 IO )
7.
**Redis 支持发布订阅模型、Lua脚本、事务等功能,而Memcached不支持。并且,Redis支持更多的编程语言。**
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached来作为自己项目的分布式缓存了。
> 来自网络上的一张图,这里分享给大家!
### 为什么要用 Redis/为什么要用缓存?
*简单,来说使用缓存主要是为了提升用户体验以及应对更多的用户。*
下面我们主要从“高性能”和“高并发”这两点来看待这个问题。

**高性能**
:
对照上面👆我画的图。我们设想这样的场景:
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
**这样有什么好处呢?**
那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
不过,要保持数据库和缓存中的数据的一致性。 如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
**高并发:**
一般像 MySQL这类的数据库的 QPS 大概都在 1w 左右(4核8g) ,但是使用 Redis 缓存之后很容易达到 10w+。
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
所以,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发。
### Redis 的线程模型
Redis 内部使用文件事件处理器
`file event handler`
,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
-
多个 socket
-
IO 多路复用程序
-
文件事件分派器
-
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
### Redis 常见数据结构以及使用场景分析
...
...
docs/database/Redis/images/redis/redis-vs-memcached.png
0 → 100644
浏览文件 @
0ebf7cae
180.0 KB
docs/database/Redis/images/redis/what-is-redis.png
0 → 100644
浏览文件 @
0ebf7cae
115.5 KB
docs/database/Redis/images/redis/使用缓存之后.png
0 → 100644
浏览文件 @
0ebf7cae
72.4 KB
docs/database/Redis/images/redis/单体架构.png
0 → 100644
浏览文件 @
0ebf7cae
17.4 KB
docs/database/Redis/images/redis/集中式缓存架构.png
0 → 100644
浏览文件 @
0ebf7cae
16.8 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}

{kind=link}
{kind=link}
{kind=link}