Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
氷泠
CSBookNotes
提交
681fc74c
C
CSBookNotes
项目概览
氷泠
/
CSBookNotes
上一次同步 1 年多
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
CSBookNotes
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
681fc74c
编写于
3月 03, 2021
作者:
2
2293736867
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
JVM chapter1 and chapter2
上级
9bb996bf
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
577 addition
and
0 deletion
+577
-0
JVM/Chapter1/README.md
JVM/Chapter1/README.md
+174
-0
JVM/Chapter2/README.md
JVM/Chapter2/README.md
+403
-0
JVM/README.md
JVM/README.md
+0
-0
未找到文件。
JVM/Chapter1/README.md
0 → 100644
浏览文件 @
681fc74c
# Table of Contents
*
[
1 来源
](
#1-来源
)
*
[
2 `Java`里程碑
](
#2-java里程碑
)
*
[
2.1 `Java`起源
](
#21-java起源
)
*
[
2.2 `JDK 1.0`
](
#22-jdk-10
)
*
[
2.3 `JDK 1.2-1.7`
](
#23-jdk-12-17
)
*
[
2.4 `JDK 1.8+`
](
#24-jdk-18
)
*
[
3 `JVM`种类简介
](
#3-jvm种类简介
)
*
[
4 `JVM`简单编译调试实战
](
#4-jvm简单编译调试实战
)
*
[
4.1 获取源码+`BootJDK`
](
#41-获取源码bootjdk
)
*
[
4.2 安装依赖库
](
#42-安装依赖库
)
*
[
4.3 编译
](
#43-编译
)
*
[
4.4 调试
](
#44-调试
)
*
[
4.5 `JVM`下载
](
#45-jvm下载
)
# 1 来源
-
来源:《Java虚拟机 JVM故障诊断与性能优化》——葛一鸣
-
章节:第一章
本文是第一章的一些笔记整理。
# 2 `Java`里程碑
## 2.1 `Java`起源
1990年
`Sun`
公司决定开发一门新的程序语言——
`Oak`
,已经具备安全性、网络通信、面向对象、垃圾回收、多线程等特性,由于
`Oak`
已被注册,于是改名为
`Java`
。
## 2.2 `JDK 1.0`
1995年
`Sun`
发布了
`Java`
以及
`HotJava`
产品,1996年正式发布
`JDK 1.0`
,包括两部分:
-
运行环境:
`JRE`
,包括核心
`API`
,用户界面
`API`
,发布技术、
`JVM`
等
-
开发环境:
`JDK`
,包括编译器
`javac`
等
1997年发布
`JDK1.1`
。
## 2.3 `JDK 1.2-1.7`
1998年发布
`JDK 1.2`
,
`JDK1.2`
兼容智能卡和小型消费类设备,还兼容大型服务器系统。同时
`Sun`
发布
`JSP/Servlet`
+
`EJB`
规范,将
`Java`
分成了
`J2EE`
、
`J2SE`
、
`J2ME`
。
2000年发布
`JDK 1.3`
,默认虚拟机改为
`Hotspot`
。
2002年发布
`JDK1.4`
,
`Classic`
虚拟机退出舞台。
2004年发布
`JDK 1.5`
,支持泛型、注解、自动装箱拆箱、枚举、可变长参数等。
2006年发布
`JDK 1.6`
,
`Java`
开源并建立了
`OpenJDK`
。
2011年发布
`JDK 1.7`
,启用了
`G1`
垃圾回收器,支持64位系统的压缩指针以及
`NIO 2.0`
。
## 2.4 `JDK 1.8+`
2014年发布
`JDK 1.8`
,
`JDK 1.8`
是一个
`LTS`
版,到目前还支持,引入了全新的
`Lambda`
。
2017年发布
`JDK 9`
。
2018年发布
`JDK 10`
。
2018年发布
`JDK 11`
,又一个
`LTS`
版,引入了字符串增强、
`Epsilon`
垃圾收集器、
`ZGC`
等。
# 3 `JVM`种类简介
`Java`
发展初期,使用的是
`Classic`
虚拟机,之后在
`Solaris`
短暂地使用过
`Exact VM`
虚拟机,到现在被大规模部署和使用的是
`Hotspot`
虚拟机。
另外,在
`IBM`
内部使用着一款叫
`J9`
的虚拟机,
`Apache`
也曾经推出过
`Apache Harmony`
,基于
`JDK 5`
以及
`JDK 6`
,于2011年停止开发。
# 4 `JVM`简单编译调试实战
下面以
`OpenJDK15`
为例,对
`OpenJDK 15 JVM`
进行源码编译。
(注:由于笔者系统为
`Manjaro`
,这是一个滚更的系统,很多工具链都会更新到最新的状态,比如
`GCC 10.2`
,书籍中的例子是利用
`JDK8`
去编译
`JDK10`
,实际测试发现会报错,
`configure`
成功了但是
`make`
失败,然后就切换到最新的
`JDK`
,就编译成功了。对于不是滚更的系统,可以使用
`JDK10`
去编译
`JDK11`
等,而非采用目前最新的
`JDK15`
)
## 4.1 获取源码+`BootJDK`
戳
[
这里
](
https://jdk.java.net/java-se-ri/15
)
下载:

可以使用如下命令检测下载文件的完整性:
```
bash
echo
"bb67cadee687d7b486583d03c9850342afea4593be4f436044d785fba9508fb7 openjdk-15+36_linux-x64_bin.tar.gz"
|
sha256sum
--check
echo
"d07bf62b4b20fa6bcd4c8fcd635e5df20b7c090af291675b2bd99f8cea8760a0 openjdk-15+36_src.zip"
|
sha256sum
--check
```
另外需要准备一个
`BootJDK`
,根据
`BootJDK`
的规则:

建议使用
`当前版本号`
/
`版本号-1`
/
`版本号-2`
的
`JDK`
,这里选用的是
`OpenJDK 15`
。
## 4.2 安装依赖库
笔者系统
`Manajro`
,需要安装一些基础依赖:
```
bash
paru
-S
base-devel
# 或
pacman
-S
base-devel
# 或
yay
-S
base-devel
```
如果依赖库安装不完整在配置阶段以及编译阶段会给出相应提示,再进行对应依赖安装即可。
## 4.3 编译
解压源码进入目录:
```
bash
unzip openjdk-15+36_src.zip
tar
-zxvf
openjdk-15+36_linux-x64_bin.tar.gz
cd
openjdk
```
配置:
```
bash
bash configure
--with-debug-level
=
slowdebug
--with-jvm-variants
=
server
--with-target-bits
=
64
--with-memory-size
=
8000
--disable-warnings-as-errors
--with-native-debug-symbols
=
internal
--with-boot-jdk
=
../jdk-15
```
参数说明:
-
`--with-debug-level=slowdebug`
:编译
`DEBUG`
版本的
`JDK`
,选项可以是
`slowdebug`
/
`fastdebug`
/
`release`
/
`optimized`
-
`--with-jvm-variants=server`
:构建
`server`
变体的
`Hotspot`
,选项可以是
`server`
/
`client`
/
`minimal`
/
`core`
/
`zero`
/
`custom`
-
`--with-target-bits=64`
:编译64位的
`JDK`
,编译32位可以使用
`--with-target-bits=32`
-
`--with-memory-size=8000`
:编译的计算机至少需要8G内存,这个可以根据个人需要调整
-
`--disable-warnings-as-errors`
:忽略警告的信息,注意该参数很重要,不加的话会显示配置成功但
`make`
失败
-
`--with-native-debug-symbols=internal`
:生成
`symbol`
文件,便于后续调试,选项可以是
`internal`
/
`none`
/
`external`
/
`zipped`
-
`--with-boot-jdk`
:
`BootJDK`
的目录
结果:
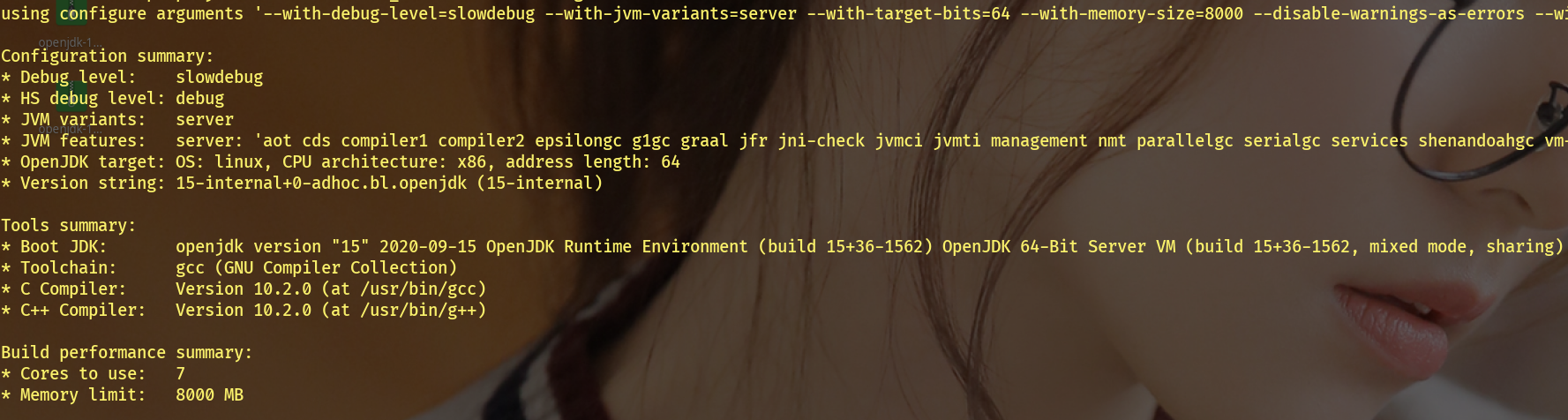
配置后进行编译:
```
bash
make images
```
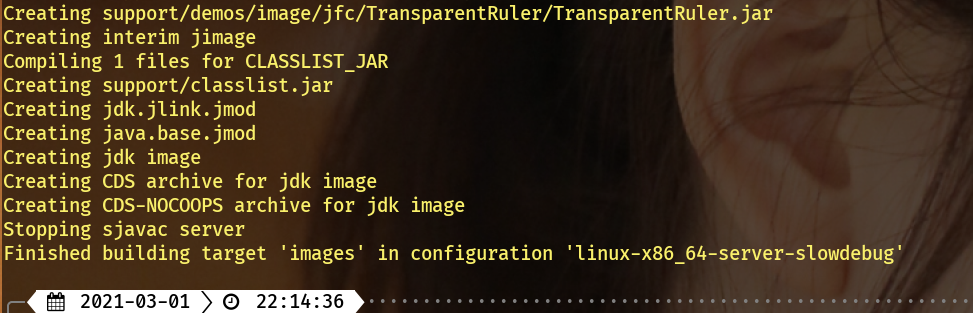
这个阶段需要一点时间,而且会把
`CPU`
拉满,好了之后会提示
`Finished building`
:
笔者环境下编译出来的
`JDK`
占了3G:
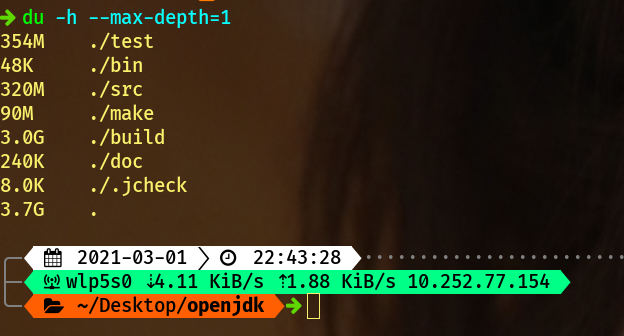
进入对应目录可以查看版本:

## 4.4 调试
调试需要
`gdb`
,先安装好
`gdb`
:
```
bash
paru
-S
gdb
```
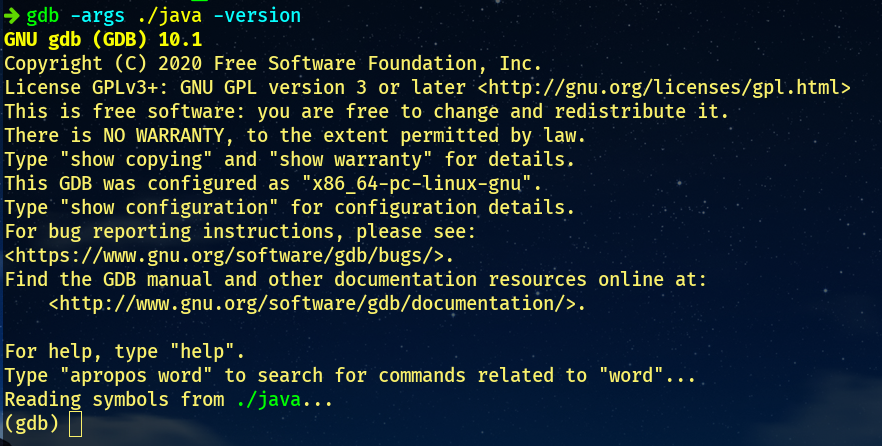
进入
`bin`
目录(
`build/linux-x86_64-server-slowdebug/jdk/bin`
),输入:
```
bash
gdb
-args
./java
-version
```
在
`main`
函数打断点:
```
bash
(
gdb
)
b main
```
再执行
`run`
,可以看到会停在
`java.base/share/native/launcher/main.c`
第98行:
```
bash
(
gdb
)
run
```
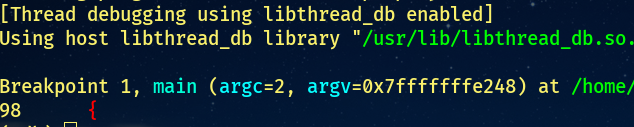
再次输入
`n`
可进行单步调试:
```
bash
(
gdb
)
n
```

这样就算完成了基础的调试操作,为进一步学习
`JVM`
准备好基本的环境。
## 4.5 `JVM`下载
如果编译失败的话,笔者这里提供了自己编译出来的
`JVM`
:
-
[
Github
](
https://github.com/2293736867/OpenJDK15FromSourceCode
)
JVM/Chapter2/README.md
0 → 100644
浏览文件 @
681fc74c
# Table of Contents
*
[
1 来源
](
#1-来源
)
*
[
2 `JVM`基本参数`-Xmx`
](
#2-jvm基本参数-xmx
)
*
[
3 `JVM`基本结构
](
#3-jvm基本结构
)
*
[
4 `Java堆`
](
#4-java堆
)
*
[
5 `Java栈`
](
#5-java栈
)
*
[
5.1 简介
](
#51-简介
)
*
[
5.2 局部变量表
](
#52-局部变量表
)
*
[
5.2.1 参数数量对局部变量表的影响
](
#521-参数数量对局部变量表的影响
)
*
[
5.2.2 槽位复用
](
#522-槽位复用
)
*
[
5.2.3 对`GC`的影响
](
#523-对gc的影响
)
*
[
5.3 操作数栈与帧数据区
](
#53-操作数栈与帧数据区
)
*
[
5.4 栈上分配
](
#54-栈上分配
)
*
[
6 `方法区`
](
#6-方法区
)
*
[
7 `Java堆`、`Java栈`以及`方法区`的关系
](
#7-java堆java栈以及方法区的关系
)
*
[
8 小结
](
#8-小结
)
# 1 来源
-
来源:《Java虚拟机 JVM故障诊断与性能优化》——葛一鸣
-
章节:第二章
本文是第二章的一些笔记整理。
# 2 `JVM`基本参数`-Xmx`
`java`
命令的一般形式如下:
```
bash
java
[
-options
]
class
[
args..]
```
其中
`-options`
表示
`JVM`
启动参数,
`class`
为带有
`main()`
的
`Java`
类,
`args`
表示传递给
`main()`
的参数,也就是
`main(String [] args)`
中的参数。
一般设置参数在
`-optinos`
处设置,先看一段简单的代码:
```
java
public
class
Main
{
public
static
void
main
(
String
[]
args
)
{
for
(
int
i
=
0
;
i
<
args
.
length
;++
i
)
{
System
.
out
.
println
(
"argument "
+(
i
+
1
)+
" : "
+
args
[
i
]);
}
System
.
out
.
println
(
"-Xmx "
+
Runtime
.
getRuntime
().
maxMemory
()/
1024
/
1024
+
" M"
);
}
}
```
设置应用程序参数以及
`JVM`
参数:

输出:
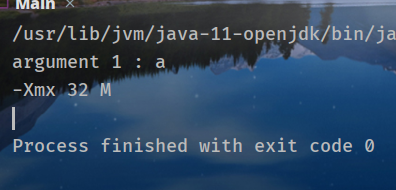

可以看到
`-Xmx32m`
传递给
`JVM`
,使得最大可用堆空间为
`32MB`
,参数
`a`
作为应用程序参数,传递给
`main()`
,此时
`args.length`
的值为1。
# 3 `JVM`基本结构
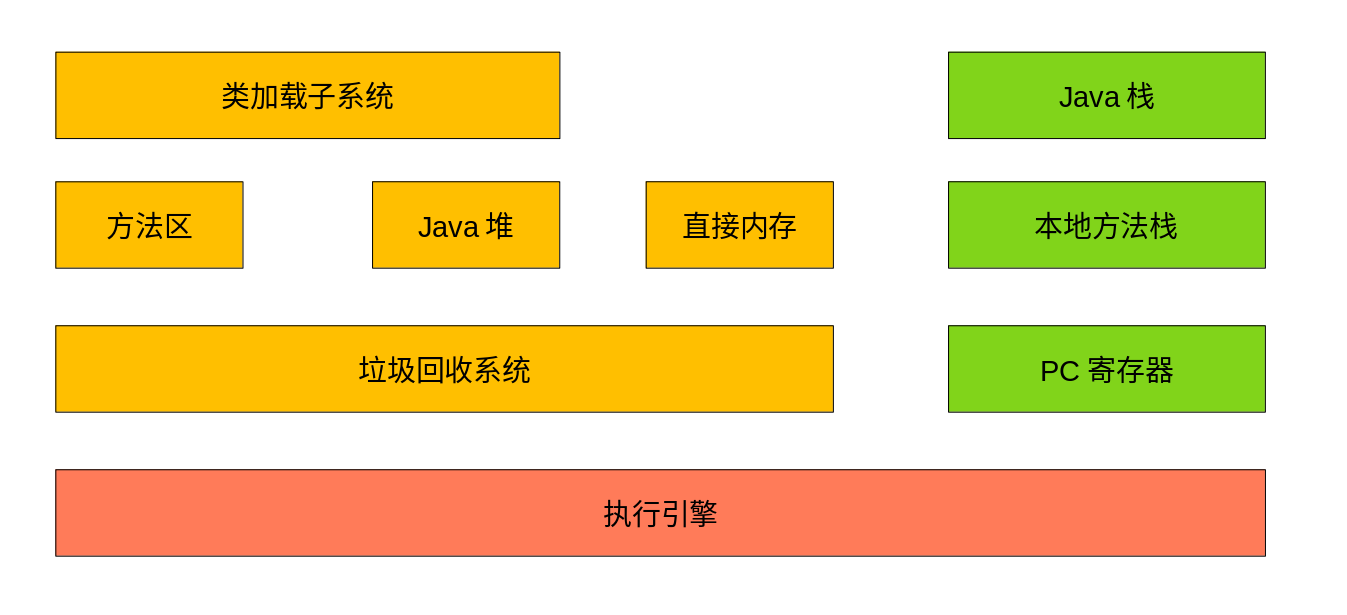
各部分介绍如下:
-
`类加载子系统`
:负责从文件系统或者网络中加载
`Class`
信息,加载的类信息存放在一个叫
`方法区`
的内存空间中
-
`方法区`
:除了包含加载的类信息之外,还包含运行时常量池信息,包括字符串字面量以及数字常量
-
`Java堆`
:在虚拟机启动时建立,是最主要的内存工作区域,几乎所有的
`Java`
对象实例都存在于
`Java堆`
中,
**堆空间是所有线程共享的**
-
`直接内存`
:是在
`Java堆`
外的,直接向系统申请的内存区域。
`NIO`
库允许
`Java`
程序使用
`直接内存`
,通常
`直接内存`
的访问速度要优于
`Java堆`
。另外由于
`直接内存`
在堆外,大小不会受限于
`-Xmx`
指定的堆大小,但是会受到操作系统总内存大小的限制
-
`垃圾回收系统`
:可以对
`方法区`
、
`Java堆`
和
`直接内存`
进行回收,
`Java堆`
是垃圾收集器的工作重点。对于不再使用的垃圾对象,
`垃圾回收系统`
会在后台默默工作、默默查找,标识并释放垃圾对象
-
`Java栈`
:每个
`JVM`
线程都有一个私有的
`Java栈`
,一个线程的
`Java栈`
在线程创建时被创建,保存着帧信息、局部变量、方法参数等
-
`本地方法栈`
:与
`Java栈`
类似,不同的是
`Java栈`
用于
`Java`
方法调用,
`本地方法栈`
用于本地方法(
`native method`
)调用,
`JVM`
允许
`Java`
直接调用本地方法
-
`PC寄存器`
:每个线程私有的空间,
`JVM`
会为每个线程创建
`PC寄存器`
,在任意时刻一个
`Java`
线程总是执行一个叫做
`当前方法`
的方法,如果
`当前方法`
不是本地方法,
`PC`
寄存器就会指向当前正在被执行的指令,如果
`当前方法`
是本地方法,那么
`PC寄存器`
的值就是
`undefined`
-
`执行引擎`
:负责执行
`JVM`
的字节码,现代
`JVM`
为了提高执行效率,会使用即时编译技术将方法编译成机器码后执行
下面重点说三部分:
`Java堆`
、
`Java栈`
以及
``
# 4 `Java堆`
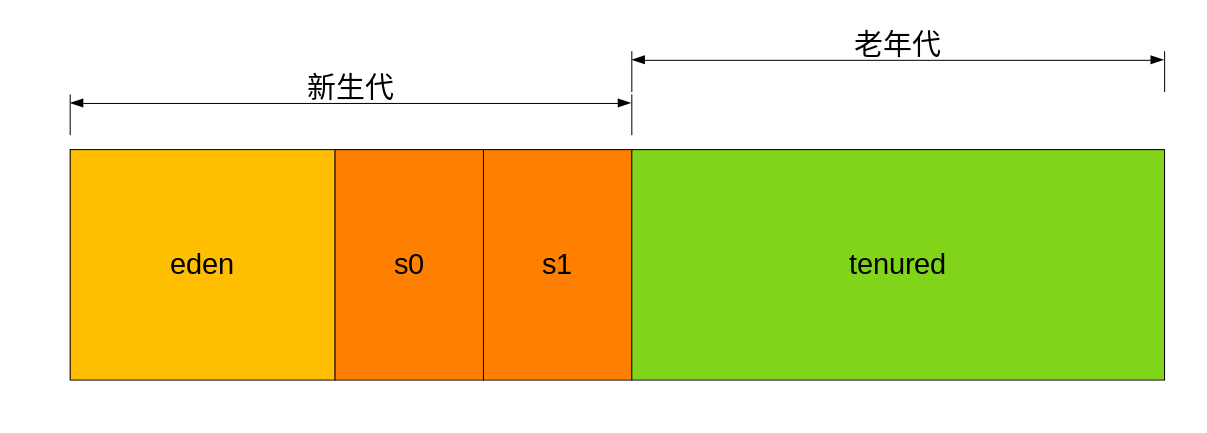
几乎所有的对象都存在`Java堆`中,根据垃圾回收机制的不同,`Java堆`可能拥有不同的结构,最常见的一种是将整个`Java堆`分为`新生代`和`老年代`:
- `新生代`:存放新生对象或年龄不大的对象,有可能分为`eden`、`s0`、`s1`,其中`s0`和`s1`分别被称为`from`和`to`区域,它们是两块大小相等、可以互换角色的内存空间
- `老年代`:存放老年对象,绝大多数情况下,对象首先在`eden`分配,在一次新生代回收后,如果对象还存活,会进入`s0`或`s1`,之后每经过一次新生代回收,如果对象存活则年龄加1。当对象年龄到达一定条件后,会被认为是老年对象,就会进入老年代
# 5 `Java栈`
## 5.1 简介
`Java栈`是一块线程私有的内存空间,如果是`Java堆`与程序数据密切相关,那么`Java栈`和线程执行密切相关,线程执行的基本行为是函数调用,每次函数调用都是通过`Java栈`传递的。
`Java栈`与数据结构中的`栈`类似,有`FIFO`的特点,在`Java`栈中保存的主要内容为**栈帧**,每次函数调用都会有一个对应的`栈帧`入栈,每次调用结束就有一个对应的`栈帧`出栈。栈顶总是当前的帧(当前执行的函数所对应的帧)。栈帧保存着`局部变量表`、`操作数栈`、`帧数据`等。
这里说一下题外话,相信很多读者对`StackOverflowError`不陌生,这是因为函数调用过多造成的,因为每次函数调用都会生成对应的栈帧,会占用一定的栈空间,如果栈空间不足,函数调用就无法进行,当请求栈深度大于最大可用栈深度时,就会抛出`StackOverflowError`。
`JVM`提供了`-Xss`来指定线程的最大栈空间。
比如,下面这个递归调用的程序:
```java
public class Main {
private static int count = 0;
public static void recursion(){
++count;
recursion();
}
public static void main(String[] args) {
try{
recursion();
}catch (StackOverflowError e){
System.out.println("Deep of calling = "+count);
}
}
}
```
指定`-Xss1m`,结果:
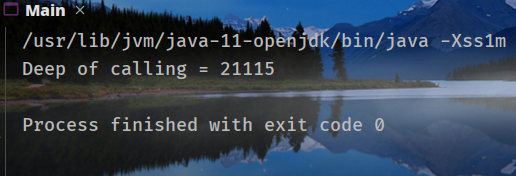
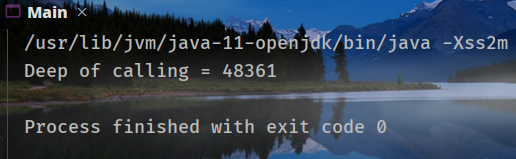
指定`-Xss2m`:
指定`-Xss3m`:
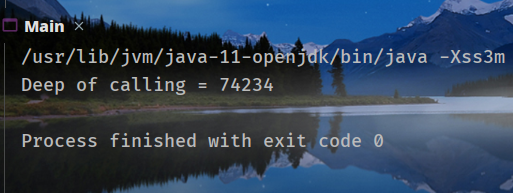
可以看到调用深度随着`-Xss`的增加而增加。
## 5.2 局部变量表
局部变量表是栈帧的重要组成部分之一,用于保存函数的参数及局部变量。局部变量表中的变量只在当前函数调用中有效,函数调用结束后,函数栈帧销毁,局部变量表也会随之销毁。
### 5.2.1 参数数量对局部变量表的影响
由于局部变量表在栈帧中,如果函数的参数和局部变量表较多,会使局部变量表膨胀,导致栈帧会占用更多的栈空间,最终减少了函数嵌套调用次数。
比如:
```java
public class Main {
private static int count = 0;
public static void recursion(long a,long b,long c){
long e=1,f=2,g=3,h=4,i=5,k=6,q=7;
count++;
recursion(a,b,c);
}
public static void recursion(){
++count;
recursion();
}
public static void main(String[] args) {
try{
// recursion();
recursion(0L,1L,2L);
}catch (StackOverflowError e){
System.out.println("Deep of calling = "+count);
count = 0;
}
}
}
```
无参数的调用次数(`-Xss1m`):
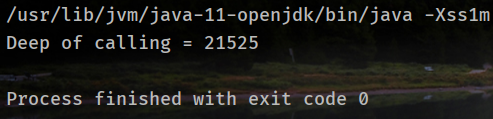
带参数的调用次数(`-Xss1m`):
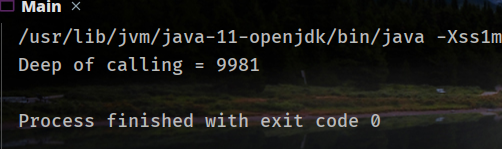
可以看到次数明显减少了,原因正是因为局部变量表变大,导致栈帧变大,从而次数减少。
下面使用`jclasslib`进一步查看,先在`IDEA`安装如下插件:
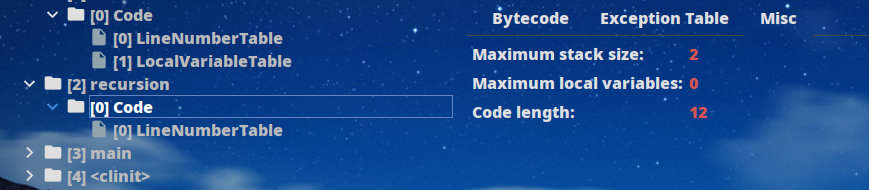
安装后使用插件查看情况:

第一个函数是带参数的,可以看到最大局部变量表的大小为`20字`(注意不是字节),`Long`在局部变量表中需要占用2字。而相比之下不带参数的函数最大局部变量表大小为0:
### 5.2.2 槽位复用
局部变量表中的槽位是可以复用的,如果一个局部变量超过了其作用域,则在其作用域之后的局部变量就有可能复用该变量的槽位,这样能够节省资源,比如:
```java
public static void localVar1(){
int a = 0;
System.out.println(a);
int b = 0;
}
public static void localVar2(){
{
int a = 0;
System.out.println(a);
}
int b = 0;
}
```
同样使用`jclasslib`查看:


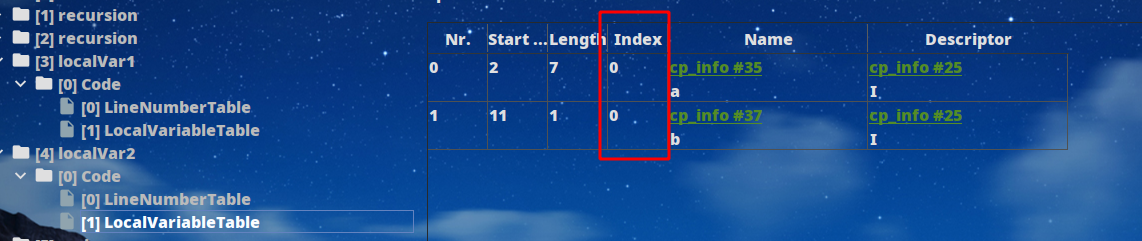
可以看到少了`localVar2`的最大局部变量大小为1字,相比`localVar1`少了1字,继续分析,`localVar1`第0个槽位为变量a,第1个槽位为变量b:

而`localVar2`中的b复用了a的槽位,因此最大变量大小为1字,节约了空间。
### 5.2.3 对`GC`的影响
下面再来看一下局部变量表对垃圾回收的影响,示例:
```java
public class Main {
public static void localGC1(){
byte [] a = new byte[6*1024*1024];
System.gc();
}
public static void localGC2(){
byte [] a = new byte[6*1024*1024];
a = null;
System.gc();
}
public static void localGC3(){
{
byte [] a = new byte[6*1024*1024];
}
System.gc();
}
public static void localGC4(){
{
byte [] a = new byte[6*1024*1024];
}
int c = 10;
System.gc();
}
public static void localGC5(){
localGC1();
System.gc();
}
public static void main(String[] args) {
System.out.println("-------------localGC1------------");
localGC1();
System.out.println();
System.out.println("-------------localGC2------------");
localGC2();
System.out.println();
System.out.println("-------------localGC3------------");
localGC3();
System.out.println();
System.out.println("-------------localGC4------------");
localGC4();
System.out.println();
System.out.println("-------------localGC5------------");
localGC5();
System.out.println();
}
}
```
输出(请加上`-Xlog:gc`参数):
```bash
[0.004s][info][gc] Using G1
-------------localGC1------------
[0.128s][info][gc] GC(0) Pause Full (System.gc()) 10M->8M(40M) 12.081ms
-------------localGC2------------
[0.128s][info][gc] GC(1) Pause Young (Concurrent Start) (G1 Humongous Allocation) 9M->8M(40M) 0.264ms
[0.128s][info][gc] GC(2) Concurrent Cycle
[0.133s][info][gc] GC(3) Pause Full (System.gc()) 16M->0M(14M) 2.799ms
[0.133s][info][gc] GC(2) Concurrent Cycle 4.701ms
-------------localGC3------------
[0.133s][info][gc] GC(4) Pause Young (Concurrent Start) (G1 Humongous Allocation) 0M->0M(14M) 0.203ms
[0.133s][info][gc] GC(5) Concurrent Cycle
[0.135s][info][gc] GC(5) Pause Remark 8M->8M(22M) 0.499ms
[0.138s][info][gc] GC(6) Pause Full (System.gc()) 8M->8M(22M) 2.510ms
[0.138s][info][gc] GC(5) Concurrent Cycle 4.823ms
-------------localGC4------------
[0.138s][info][gc] GC(7) Pause Young (Concurrent Start) (G1 Humongous Allocation) 8M->8M(22M) 0.202ms
[0.138s][info][gc] GC(8) Concurrent Cycle
[0.142s][info][gc] GC(9) Pause Full (System.gc()) 16M->0M(8M) 2.861ms
[0.142s][info][gc] GC(8) Concurrent Cycle 3.953ms
-------------localGC5------------
[0.143s][info][gc] GC(10) Pause Young (Concurrent Start) (G1 Humongous Allocation) 0M->0M(8M) 0.324ms
[0.143s][info][gc] GC(11) Concurrent Cycle
[0.145s][info][gc] GC(11) Pause Remark 8M->8M(16M) 0.316ms
[0.147s][info][gc] GC(12) Pause Full (System.gc()) 8M->8M(18M) 2.402ms
[0.149s][info][gc] GC(13) Pause Full (System.gc()) 8M->0M(8M) 2.462ms
[0.149s][info][gc] GC(11) Concurrent Cycle 6.843ms
```
首行输出表示使用`G1`,下面逐个进行分析:
- `localGC1`:并没有回收内存,因为此时`byte`数组被变量`a`引用,因此无法回收
- `localGC2`:回收了内存,因为`a`被设置为了`null`,`byte`数组失去强引用
- `localGC3`:没有回收内存,虽然此时`a`变量已经失效,但是仍然存在于局部变量表中,并且指向`byte`数组,因此无法回收
- `localGC4`:回收了内存,因为声明了变量`c`,复用了`a`的槽位,导致`byte`数组失去引用,顺利回收
- `localGC5`:回收了内存,虽然`localGC1`中没有释放内存,但是返回到`localGC5`后,`localGC1`的栈帧被销毁,也包括其中的`byte`数组失去了引用,因此在`localGC5`中被回收
## 5.3 操作数栈与帧数据区
操作数栈也是栈帧的重要内容之一,主要用于保存计算过程的中间结果,同时作为计算过程中变量的临时存储空间,也是一个`FIFO`的数据结构。
而帧数据区则保存着常量池指针,方便程序访问常量池,此外,帧数据区也保存着异常处理表,以便在出现异常后,找到处理异常的代码。
## 5.4 栈上分配
栈上分配是`JVM`提供的一项优化技术,基本思想是,将线程私有的对象打散分配到栈上,好处是函数调用结束后可以自动销毁,而不需要垃圾回收器的介入,从而提高系统性能。
栈上分配的一个技术基础是逃逸分析,逃逸分析目的是判断对象的作用域是否会逃逸出函数体,例子如下:
```java
public class Main {
private static int count = 0;
public static class User{
public int id = 0;
public String name = "";
}
public static void alloc(){
User user = new User();
user.id = 5;
user.name = "test";
}
public static void main(String[] args) {
long b = System.currentTimeMillis();
for (int i = 0; i < 1000000000; i++) {
alloc();
}
long e = System.currentTimeMillis();
System.out.println(e-b);
}
}
```
启动参数:
```bash
-server # 开启Server模式,此模式下才能开启逃逸分析
-Xmx10m # 最大堆内存
-Xms10m # 初始化堆内存
-XX:+DoEscapeAnalysis # 开启逃逸分析
-Xlog:gc # GC日志
-XX:-UseTLAB # 关闭TLAB
-XX:+EliminateAllocations # 开启标量替换,默认打开,允许将对象打散分配在栈上
```
输出如下,没有`GC`日志:

而如果关闭了标量替换,也就是添加`-XX:-EliminateAllocations`,就可以看到会频繁触发`GC`,因为这时候对象存放在堆上而不是栈上,堆只有10m空间,会频繁进行`GC`:

# 6 `方法区`
与`Java堆`一样,`方法区`是所有线程共享的内存区域,用于保存系统的类信息,比如类字段、方法、常量池等,`方法区`的大小决定了系统可以保存多少个类,如果定义了过多的类,会导致`方法区`溢出,会直接`OOM`。
在`JDK6/7`中`方法区`可以理解成`永久区`,`JDK8`后,`永久区`被移除,取而代之的是`元数据区`,可以使用`-XX:MaxMetaspaceSize`指定,这是一块堆外的直接内存,如果不指定大小,默认情况下`JVM`会耗尽所有可用的系统内存。
如果`元数据区`发生溢出,`JVM`会抛出`OOM`。
# 7 `Java堆`、`Java栈`以及`方法区`的关系
看完了`Java堆`、`Java栈`以及`方法区`,最后来一段代码来简单分析一下它们的关系:
```java
class SimpleHeap{
private int id;
public SimpleHeap(int id){
this.id = id;
}
public void show(){
System.out.println("id is "+id);
}
public static void main(String[] args) {
SimpleHeap s1 = new SimpleHeap(1);
SimpleHeap s2 = new SimpleHeap(2);
s1.show();
s2.show();
}
}
```
`
main
`中创建了两个局部变量`
s1
`、`
s2
`,则这两个局部变量存放在`
Java栈
`中。同时这两个局部变量是`
SimpleHeap
`的实例,这两个实例存放在`
Java堆
`中,而其中的`
show
`方法,则存放与`
方法区
`中,图示如下:
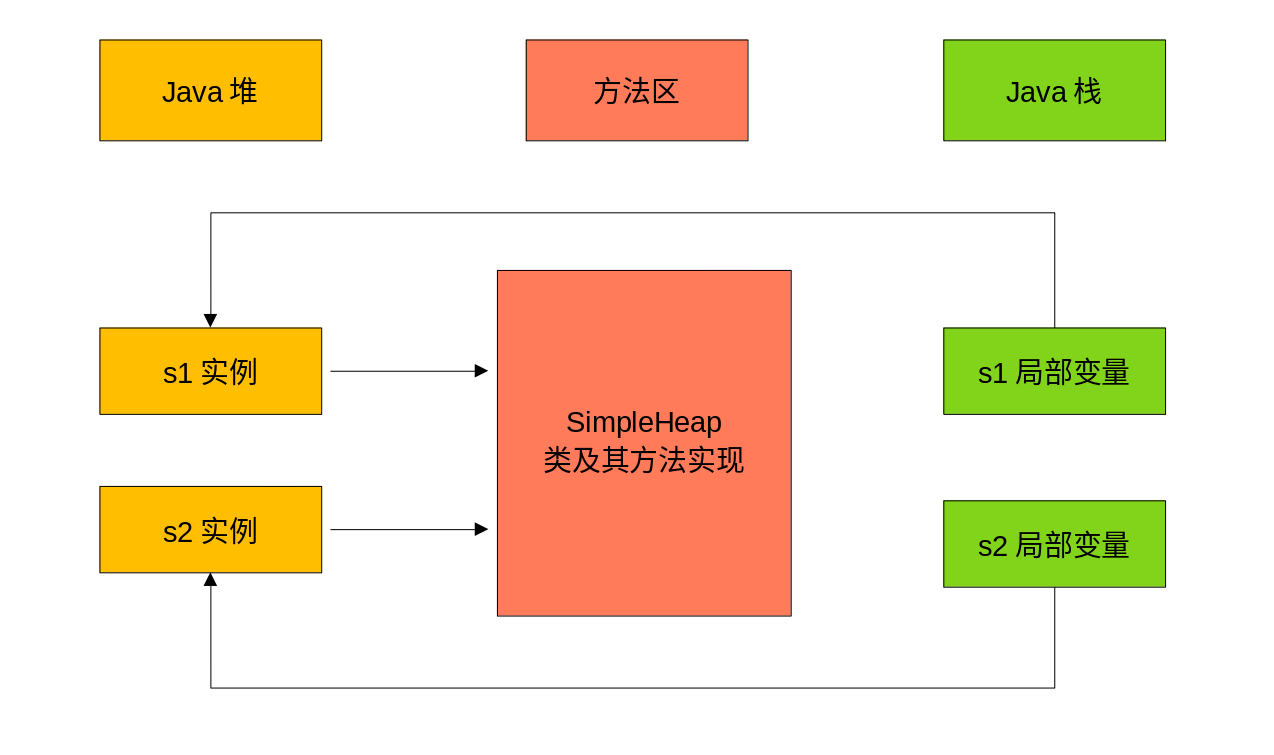
# 8 小结
本文主要讲述了`
JVM
`的基本结构以及一些基础参数,基本结构可以分成三部分:
- 第一部分:`
类加载子系统
`、`
Java堆
`、`
方法区
`、`
直接内存
`
- 第二部分:`
Java栈
`、`
本地方法栈
`、`
PC寄存器
`
- 第三部分:执行引擎
而重点讲了三部分:
- `
Java堆
`:常见的结构为`
新生代
`+`
老年代
`结构,其中新生代可分为`
edsn
`、`
s0
`、`
s1
`
- `
Java栈
`:包括局部变量表、操作数栈与帧数据区,还提到了一个`
JVM
`优化技术栈上分配,可以通过`
-XX:+EliminateAllocation
`开启(默认开启)
- `
方法区
`
:所有线程共享区域,用于保存类信息,比如类字段、方法、常量等
JVM/README.md
0 → 100644
浏览文件 @
681fc74c
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录