更新一篇我爱计算机视觉文章
推荐几篇新出的 CVPR 2021开源论文,含图像分割、域适应、图像检索、视线估计等
Showing
我爱计算机视觉/imgs/1.jpg
0 → 100644
{kind=link}

62.2 KB
我爱计算机视觉/imgs/1.webp
0 → 100644
{kind=link}
文件已添加
我爱计算机视觉/imgs/2.jpg
0 → 100644
{kind=link}

168.3 KB
我爱计算机视觉/imgs/2.webp
0 → 100644
{kind=link}
文件已添加
我爱计算机视觉/imgs/3.jpg
0 → 100644
{kind=link}
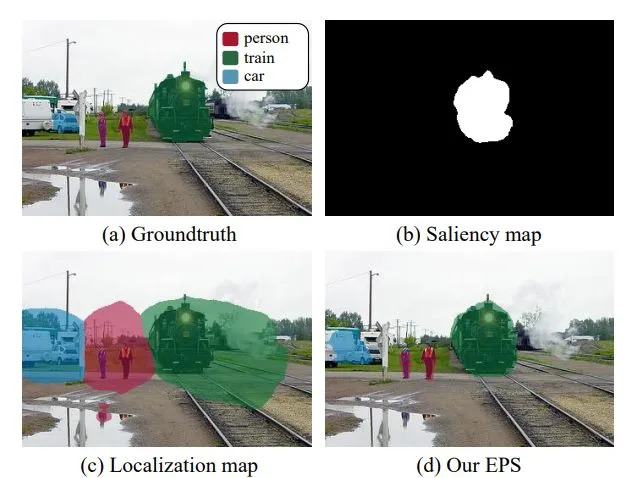
72.5 KB
我爱计算机视觉/imgs/3.webp
0 → 100644
{kind=link}
文件已添加
我爱计算机视觉/imgs/4.png
0 → 100644
{kind=link}

385.2 KB
我爱计算机视觉/imgs/5.jpg
0 → 100644
{kind=link}
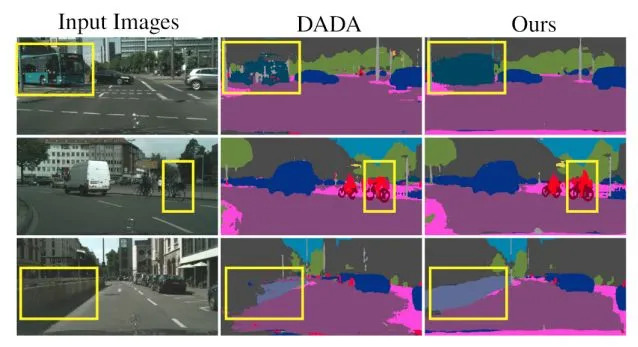
64.4 KB
我爱计算机视觉/imgs/5.webp
0 → 100644
{kind=link}
文件已添加
我爱计算机视觉/imgs/6.jpg
0 → 100644
{kind=link}
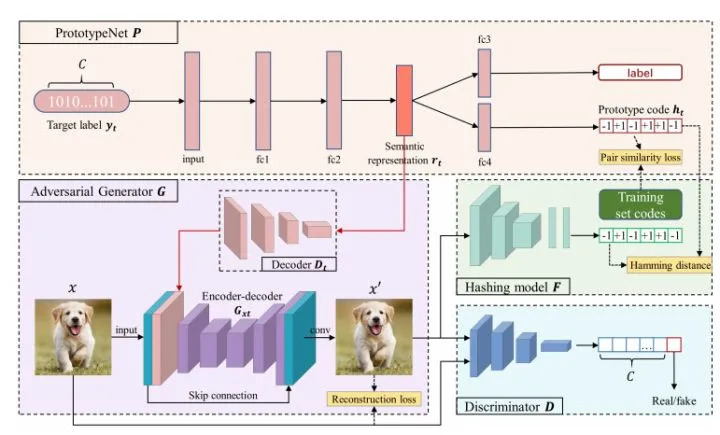
76.9 KB
我爱计算机视觉/imgs/6.webp
0 → 100644
{kind=link}
文件已添加
我爱计算机视觉/imgs/7.jpg
0 → 100644
{kind=link}
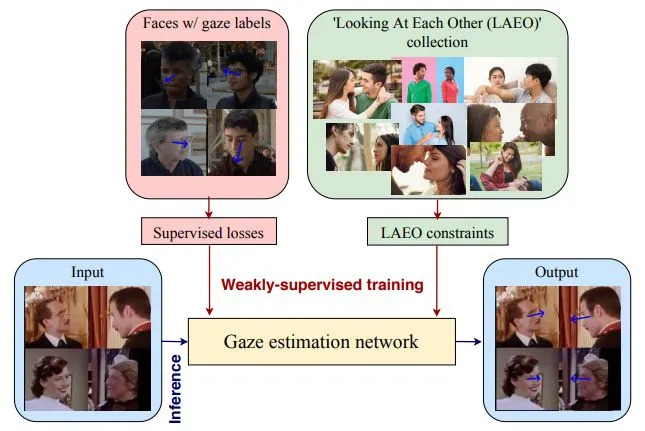
76.3 KB
我爱计算机视觉/imgs/7.webp
0 → 100644
{kind=link}
文件已添加
我爱计算机视觉/imgs/8.jpg
0 → 100644
{kind=link}

48.2 KB
我爱计算机视觉/imgs/8.webp
0 → 100644
{kind=link}
文件已添加