3.[Requirements and Dependencies](#requirements-and-dependencies)
4.[Clone OpenPose](#clone-openpose)
5.[Update OpenPose](#update-openpose)
6.[Installation](#installation)
7.[Reinstallation](#reinstallation)
8.[Uninstallation](#uninstallation)
9.[Optional Settings](#optional-settings)
3.[Community-Based Work](#community-based-work)
4.[Requirements and Dependencies](#requirements-and-dependencies)
5.[Clone OpenPose](#clone-openpose)
6.[Update OpenPose](#update-openpose)
7.[Installation](#installation)
8.[Reinstallation](#reinstallation)
9.[Uninstallation](#uninstallation)
10.[Optional Settings](#optional-settings)
1.[Maximum Speed](#maximum-speed)
2.[COCO and MPI Models](#coco-and-mpi-models)
3.[Python API](#python-api)
...
...
@@ -46,6 +47,22 @@ This installation section is only intended if you plan to modify the OpenPose co
## Community-Based Work
We add links to some community-based work based on OpenPose. Note: We do not support them, and we will remove GitHub issues opened asking about them as well as block those users from posting again. If you face any issue, comment only in the comment IDs especified below and/or on their respective GitHubs.
-[ROS example](https://github.com/firephinx/openpose_ros)(based on a very old OpenPose version). For questions and more details, read and post ONLY on [issue thread #51](https://github.com/CMU-Perceptual-Computing-Lab/openpose/issues/51).
- Docker Images. For questions and more details, read and post ONLY on [issue thread #347](https://github.com/CMU-Perceptual-Computing-Lab/openpose/issues/347).
- Dockerfile working with CUDA 10: [link 1](https://github.com/ExSidius/openpose-docker/blob/master/Dockerfile) and [link 2](https://cloud.docker.com/repository/docker/exsidius/openpose/general).
-[Dockerfile - OpenPose v1.4.0, OpenCV, CUDA 8, CuDNN 6, Python2.7](https://gist.github.com/moiseevigor/11c02c694fc0c22fccd59521793aeaa6).
-[Google Colab helper script](https://github.com/CMU-Perceptual-Computing-Lab/openpose/issues/949#issue-387855863): Script to install OpenPose on Google Colab. Really useful when access to a computer powerful enough to run OpenPose is not possible, so one possible way to use OpenPose is to build it on a GPU-enabled Colab runtime and then run the programs there. For questions and more details, read and post ONLY on [issue thread #949](https://github.com/CMU-Perceptual-Computing-Lab/openpose/issues/949).
## Requirements and Dependencies
-**Requirements** for the default configuration (you might need more resources with a greater `--net_resolution` and/or `scale_number` or less resources by reducing the net resolution and/or using the MPI and MPI_4 models):
- CUDA (Nvidia GPU) version:
...
...
@@ -122,10 +139,11 @@ Make sure to download and install the prerequisites for your particular operatin
2. Press the `Configure` button, keep the generator in `Unix Makefile` (Ubuntu) or set it to `Visual Studio 14 2015 Win64` (Windows), and press `Finish`.
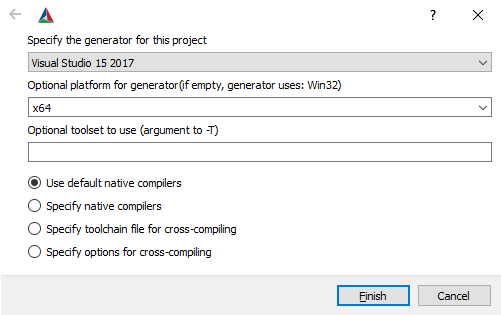
2. Press the `Configure` button, keep the generator in `Unix Makefile` (Ubuntu) or set it to your 64-bit Visual Studio version (Windows), and press `Finish`. Note for Windows users: CMake-GUI has changed their design after version 14. For versions older than 14, you usually select `Visual Studio XX 20XX Win64` as the generator (`X` depends on your VS version), while the `Optional toolset to use` must be empty. However, new CMake versions require you to select only the VS version as the generator, e.g., `Visual Studio 15 2017`, and then you must manually choose `x64` for the `Optional platform for generator`. See the following images as example.
3. If this step is successful, the `Configuring done` text will appear in the bottom box in the last line. Otherwise, some red text will appear in that same bottom box.
{kind=link}