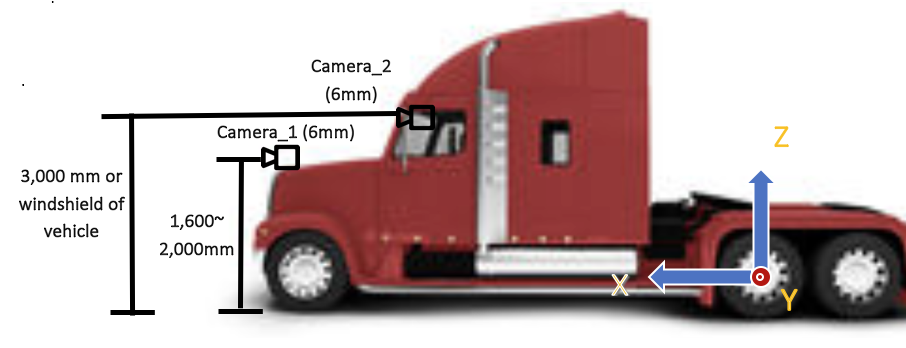
Perception: Added documents about perception algorithms and sensor installation guidelines
Showing
{kind=link}
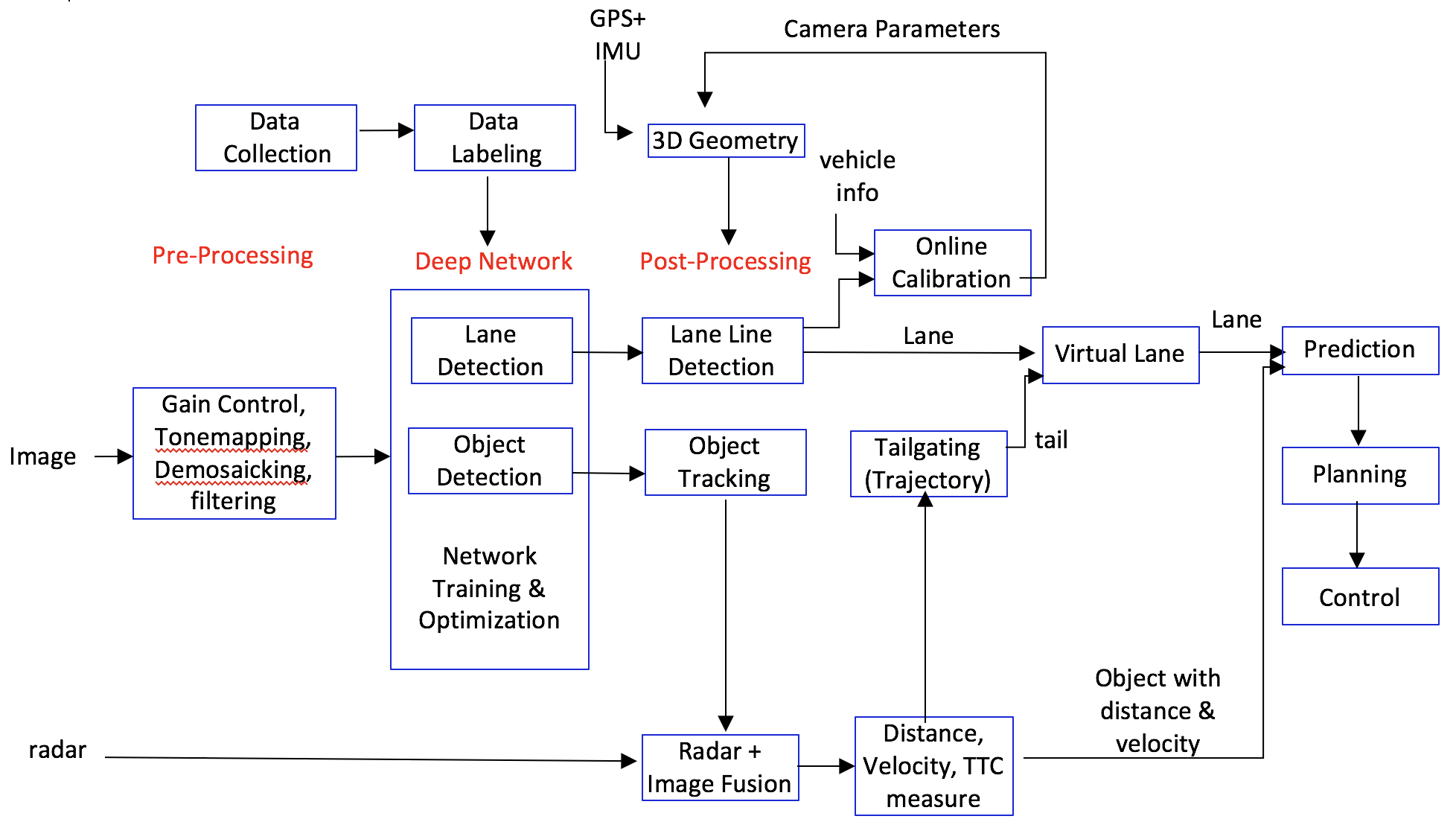
183.8 KB
{kind=link}

33.7 KB
{kind=link}
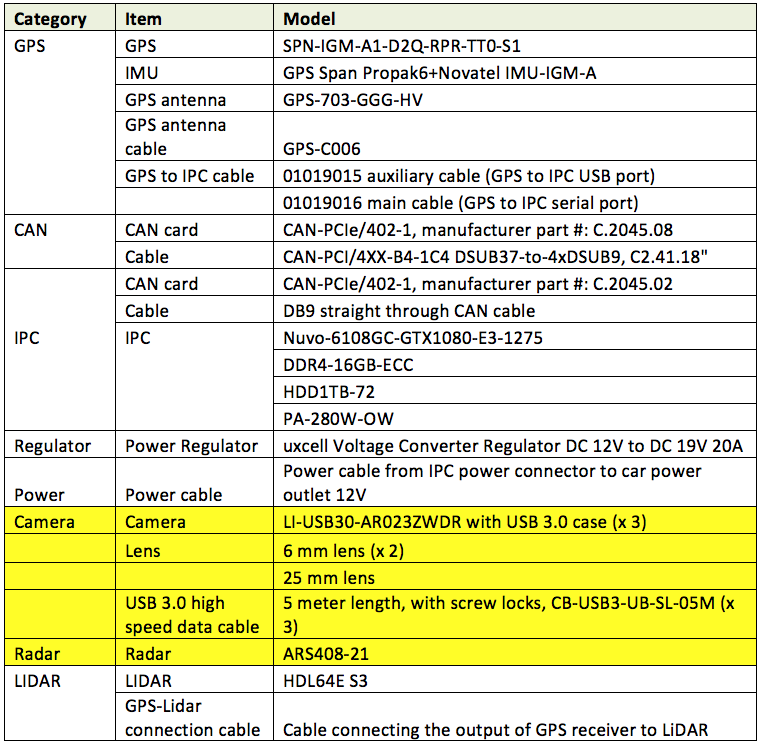
146.6 KB
{kind=link}
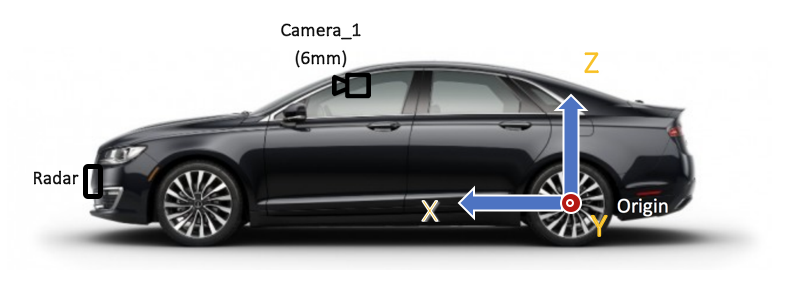
136.2 KB
{kind=link}
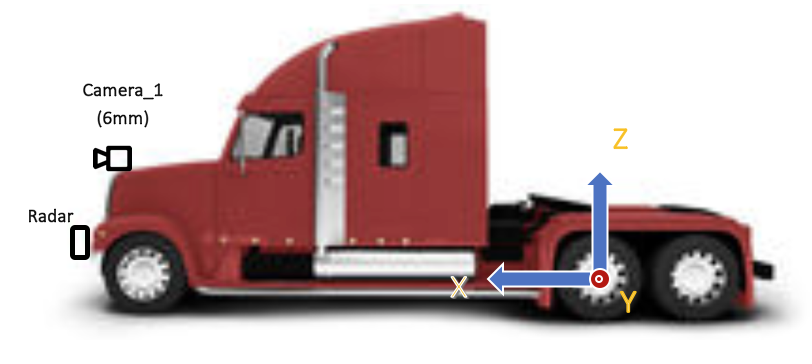
195.2 KB
{kind=link}
202.4 KB
{kind=link}

357.6 KB
从无法访问的项目Fork
183.8 KB
33.7 KB
146.6 KB
136.2 KB
195.2 KB
202.4 KB
357.6 KB