Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
wushizhenking
advanced-java
提交
b2f9168a
A
advanced-java
项目概览
wushizhenking
/
advanced-java
与 Fork 源项目一致
从无法访问的项目Fork
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
A
advanced-java
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
b2f9168a
编写于
12月 26, 2018
作者:
Y
yanglbme
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
docs: add hystrix-thread-pool-isolation.md
Hystrix 线程池技术实现资源隔离 Redis 小修改
上级
429a6b63
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
121 addition
and
4 deletion
+121
-4
README.md
README.md
+1
-0
docs/high-availability/hystrix-thread-pool-isolation.md
docs/high-availability/hystrix-thread-pool-isolation.md
+116
-0
docs/high-availability/img/hystrix-thread-pool-isolation.png
docs/high-availability/img/hystrix-thread-pool-isolation.png
+0
-0
docs/high-concurrency/redis-consistence.md
docs/high-concurrency/redis-consistence.md
+1
-1
docs/high-concurrency/redis-expiration-policies-and-lru.md
docs/high-concurrency/redis-expiration-policies-and-lru.md
+3
-3
img/hystrix-thread-pool-isolation.png
img/hystrix-thread-pool-isolation.png
+0
-0
未找到文件。
README.md
浏览文件 @
b2f9168a
...
...
@@ -82,6 +82,7 @@
## 高可用架构
-
[
Hystrix 介绍
](
/docs/high-availability/hystrix-introduction.md
)
-
[
电商网站详情页系统架构
](
/docs/high-availability/e-commerce-website-detail-page-architecture.md
)
-
[
Hystrix 线程池技术实现资源隔离
](
/docs/high-availability/hystrix-thread-pool-isolation.md
)
### 高可用系统
-
如何设计一个高可用系统?
...
...
docs/high-availability/hystrix-thread-pool-isolation.md
0 → 100644
浏览文件 @
b2f9168a
## 基于 Hystrix 线程池技术实现资源隔离
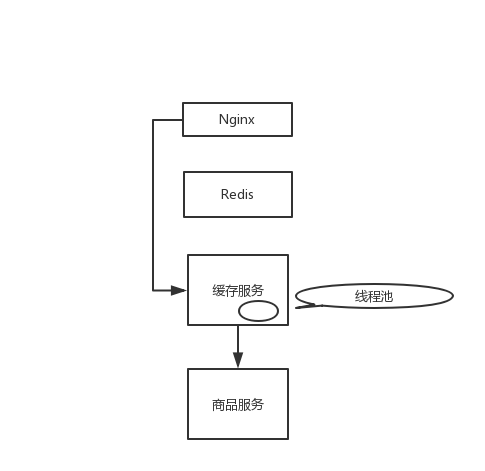
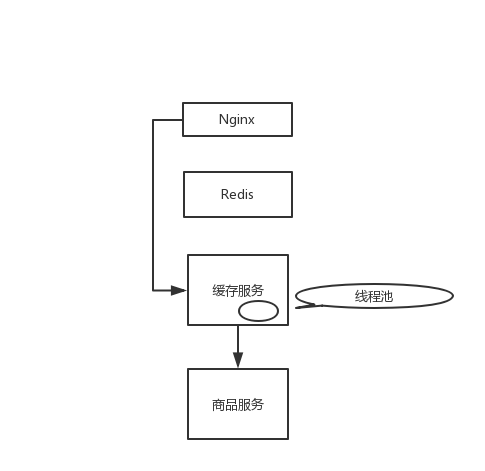
上一讲提到,如果从 Nginx 开始,缓存都失效了,Nginx 会直接通过缓存服务调用商品服务获取最新商品数据(我们基于电商项目做个讨论),有可能出现调用延时而把缓存服务资源耗尽的情况。这里,我们就来说说,怎么通过 Hystrix 线程池技术实现资源隔离。
资源隔离,就是说,你如果要把对某一个依赖服务的所有调用请求,全部隔离在同一份资源池内,不会去用其它资源了,这就叫资源隔离。哪怕对这个依赖服务,比如说商品服务,现在同时发起的调用量已经到了 1000,但是线程池内就 10 个线程,最多就只会用这 10 个线程去执行,不会说,对商品服务的请求,因为接口调用延时,将 tomcat 内部所有的线程资源全部耗尽。
Hystrix 进行资源隔离,其实是提供了一个抽象,叫做 command。这也是 Hystrix 最最基本的资源隔离技术。
### 利用 HystrixCommand 获取单条数据
我们通过将调用商品服务的操作封装在 HystrixCommand 中,限定一个 key,比如下面的
`GetProductInfoCommandGroup`
,在这里我们可以简单认为这是一个线程池,每次调用商品服务,就只会用该线程池中的资源,不会再去用其它线程资源了。
```
java
public
class
GetProductInfoCommand
extends
HystrixCommand
<
ProductInfo
>
{
private
Long
productId
;
public
GetProductInfoCommand
(
Long
productId
)
{
super
(
HystrixCommandGroupKey
.
Factory
.
asKey
(
"GetProductInfoCommandGroup"
));
this
.
productId
=
productId
;
}
@Override
protected
ProductInfo
run
()
{
String
url
=
"http://localhost:8081/getProductInfo?productId="
+
productId
;
// 调用商品服务接口
String
response
=
HttpClientUtils
.
sendGetRequest
(
url
);
return
JSONObject
.
parseObject
(
response
,
ProductInfo
.
class
);
}
}
```
我们在缓存服务接口中,根据 productId 创建 command 并执行,获取到商品数据。
```
java
@RequestMapping
(
"/getProductInfo"
)
@ResponseBody
public
String
getProductInfo
(
Long
productId
)
{
HystrixCommand
<
ProductInfo
>
getProductInfoCommand
=
new
GetProductInfoCommand
(
productId
);
// 通过command执行,获取最新商品数据
ProductInfo
productInfo
=
getProductInfoCommand
.
execute
();
System
.
out
.
println
(
productInfo
);
return
"success"
;
}
```
上面执行的是 execute() 方法,其实是同步的。也可以对 command 调用 queue() 方法,它仅仅是将 command 放入线程池的一个等待队列,就立即返回,拿到一个 Future 对象,后面可以继续做其它一些事情,然后过一段时间对 Future 调用 get() 方法获取数据。这是异步的。
### 利用 HystrixObservableCommand 批量获取数据
只要是获取商品数据,全部都绑定到同一个线程池里面去,我们通过 HystrixObservableCommand 的一个线程去执行,而在这个线程里面,批量把多个 productId 的 productInfo 拉回来。
```
java
public
class
GetProductInfosCommand
extends
HystrixObservableCommand
<
ProductInfo
>
{
private
String
[]
productIds
;
public
GetProductInfosCommand
(
String
[]
productIds
)
{
// 还是绑定在同一个线程池
super
(
HystrixCommandGroupKey
.
Factory
.
asKey
(
"GetProductInfoGroup"
));
this
.
productIds
=
productIds
;
}
@Override
protected
Observable
<
ProductInfo
>
construct
()
{
return
Observable
.
unsafeCreate
((
Observable
.
OnSubscribe
<
ProductInfo
>)
subscriber
->
{
for
(
String
productId
:
productIds
)
{
// 批量获取商品数据
String
url
=
"http://localhost:8081/getProductInfo?productId="
+
productId
;
String
response
=
HttpClientUtils
.
sendGetRequest
(
url
);
ProductInfo
productInfo
=
JSONObject
.
parseObject
(
response
,
ProductInfo
.
class
);
subscriber
.
onNext
(
productInfo
);
}
subscriber
.
onCompleted
();
}).
subscribeOn
(
Schedulers
.
io
());
}
}
```
在缓存服务接口中,根据传来的 id 列表,比如是以
`,`
分隔的 id 串,通过上面的 HystrixObservableCommand,执行 Hystrix 的一些 API 方法,获取到所有商品数据。
```
java
public
String
getProductInfos
(
String
productIds
)
{
String
[]
productIdArray
=
productIds
.
split
(
","
);
HystrixObservableCommand
<
ProductInfo
>
getProductInfosCommand
=
new
GetProductInfosCommand
(
productIdArray
);
Observable
<
ProductInfo
>
observable
=
getProductInfosCommand
.
observe
();
observable
.
subscribe
(
new
Observer
<
ProductInfo
>()
{
@Override
public
void
onCompleted
()
{
System
.
out
.
println
(
"获取完了所有的商品数据"
);
}
@Override
public
void
onError
(
Throwable
e
)
{
e
.
printStackTrace
();
}
/**
* 获取完一条数据,就回调一次这个方法
* @param productInfo
*/
@Override
public
void
onNext
(
ProductInfo
productInfo
)
{
System
.
out
.
println
(
productInfo
);
}
});
return
"success"
;
}
```
我们回过头来,看看 Hystrix 线程池技术是如何实现资源隔离的。

从 Nginx 开始,缓存都失效了,那么 Nginx 通过缓存服务去调用商品服务。缓存服务默认的线程大小是 10 个,最多就只有 10 个线程去调用商品服务的接口。即使商品服务接口故障了,最多就只有 10 个线程会 hang 死在调用商品服务接口的路上,缓存服务的 tomcat 内其它的线程还是可以用来调用其它的服务,干其它的事情。
\ No newline at end of file
docs/high-availability/img/hystrix-thread-pool-isolation.png
0 → 100644
浏览文件 @
b2f9168a
12.3 KB
docs/high-concurrency/redis-consistence.md
浏览文件 @
b2f9168a
...
...
@@ -22,7 +22,7 @@
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于
**比较复杂的缓存数据计算的场景**
,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,
**这个缓存到底会不会被频繁访问到?**
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次
,
100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有
**大量的冷数据**
。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。
**用到缓存才去算缓存。**
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次
、
100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有
**大量的冷数据**
。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。
**用到缓存才去算缓存。**
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
...
...
docs/high-concurrency/redis-expiration-policies-and-lru.md
浏览文件 @
b2f9168a
...
...
@@ -27,7 +27,7 @@ redis 过期策略是:**定期删除+惰性删除**。
但是问题是,定期删除可能会导致很多过期 key 到了时间并没有被删除掉,那咋整呢?所以就是惰性删除了。这就是说,在你获取某个 key 的时候,redis 会检查一下 ,这个 key 如果设置了过期时间那么是否过期了?如果过期了此时就会删除,不会给你返回任何东西。
> 获取key 的时候,如果此时 key 已经过期,就删除,不会返回任何东西。
> 获取
key 的时候,如果此时 key 已经过期,就删除,不会返回任何东西。
但是实际上这还是有问题的,如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期 key 堆积在内存里,导致 redis 内存块耗尽了,咋整?
...
...
@@ -36,9 +36,9 @@ redis 过期策略是:**定期删除+惰性删除**。
### 内存淘汰机制
redis 内存淘汰机制有以下几个:
-
noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
-
**allkeys-lru**
:当内存不足以容纳新写入数据时,在
**键空间**
中,移除最近最少使用的 key(这个是
**最常用**
的)
-
**allkeys-lru**
:当内存不足以容纳新写入数据时,在
**键空间**
中,移除最近最少使用的 key(这个是
**最常用**
的)
。
-
allkeys-random:当内存不足以容纳新写入数据时,在
**键空间**
中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
-
volatile-lru:当内存不足以容纳新写入数据时,在
**设置了过期时间的键空间**
中,移除最近最少使用的 key(这个一般不太合适)
-
volatile-lru:当内存不足以容纳新写入数据时,在
**设置了过期时间的键空间**
中,移除最近最少使用的 key(这个一般不太合适)
。
-
volatile-random:当内存不足以容纳新写入数据时,在
**设置了过期时间的键空间**
中,
**随机移除**
某个 key。
-
volatile-ttl:当内存不足以容纳新写入数据时,在
**设置了过期时间的键空间**
中,有
**更早过期时间**
的 key 优先移除。
...
...
img/hystrix-thread-pool-isolation.png
0 → 100644
浏览文件 @
b2f9168a
12.3 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}