initial version
Signed-off-by: Nleonwanghui <leon.wanghui@huawei.com>
上级
Showing
.clang-format
0 → 100644
.gitignore
0 → 100644
.gitmodules
0 → 100644
CMakeLists.txt
0 → 100644
CONTRIBUTING.md
0 → 100644
LICENSE
0 → 100644
NOTICE
0 → 100644
README.md
0 → 100644
RELEASE.md
0 → 100644
SECURITY.md
0 → 100644
因为 它太大了无法显示 source diff 。你可以改为 查看blob。
autogen.sh
0 → 100755
build.sh
0 → 100755
cmake/dependency_gtest.cmake
0 → 100644
cmake/dependency_protobuf.cmake
0 → 100644
cmake/dependency_securec.cmake
0 → 100644
cmake/dependency_utils.cmake
0 → 100644
cmake/external_libs/dlpack.cmake
0 → 100644
cmake/external_libs/eigen.cmake
0 → 100644
cmake/external_libs/glog.cmake
0 → 100644
cmake/external_libs/gtest.cmake
0 → 100644
cmake/external_libs/json.cmake
0 → 100644
cmake/external_libs/libtiff.cmake
0 → 100644
cmake/external_libs/mkl_dnn.cmake
0 → 100644
cmake/external_libs/nccl.cmake
0 → 100644
cmake/external_libs/ompi.cmake
0 → 100644
cmake/external_libs/onnx.cmake
0 → 100644
cmake/external_libs/opencv.cmake
0 → 100644
cmake/external_libs/rang.cmake
0 → 100644
cmake/external_libs/sqlite.cmake
0 → 100644
cmake/external_libs/tvm_gpu.cmake
0 → 100644
cmake/mind_expression.cmake
0 → 100644
cmake/options.cmake
0 → 100644
cmake/utils.cmake
0 → 100644
config/e2e_dump_config.json
0 → 100644
config/e2e_dump_config_0.json
0 → 100644
config/e2e_dump_config_1.json
0 → 100644
config/hccl_evb_multi_rank.json
0 → 100644
dbg_dump_parser.sh
0 → 100755
{kind=link}

76.0 KB
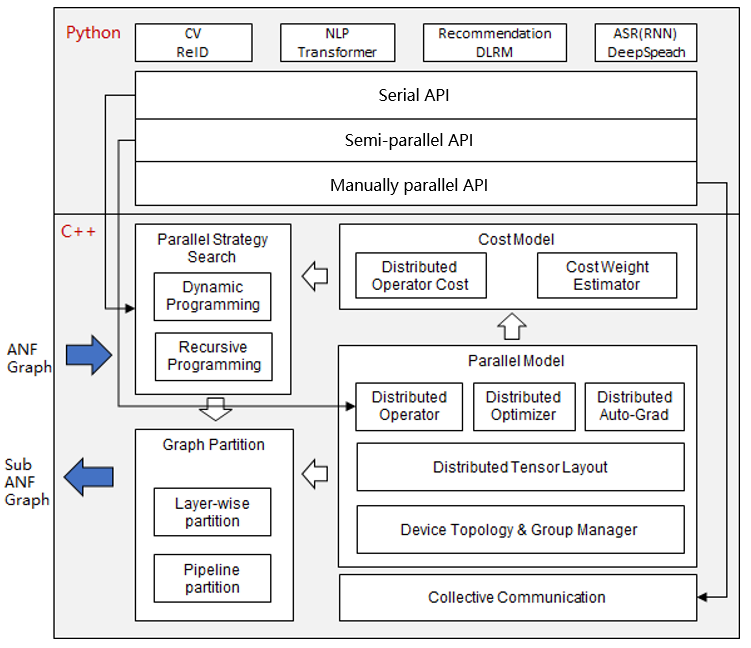
docs/Automatic-parallel.png
0 → 100644
{kind=link}
121.1 KB
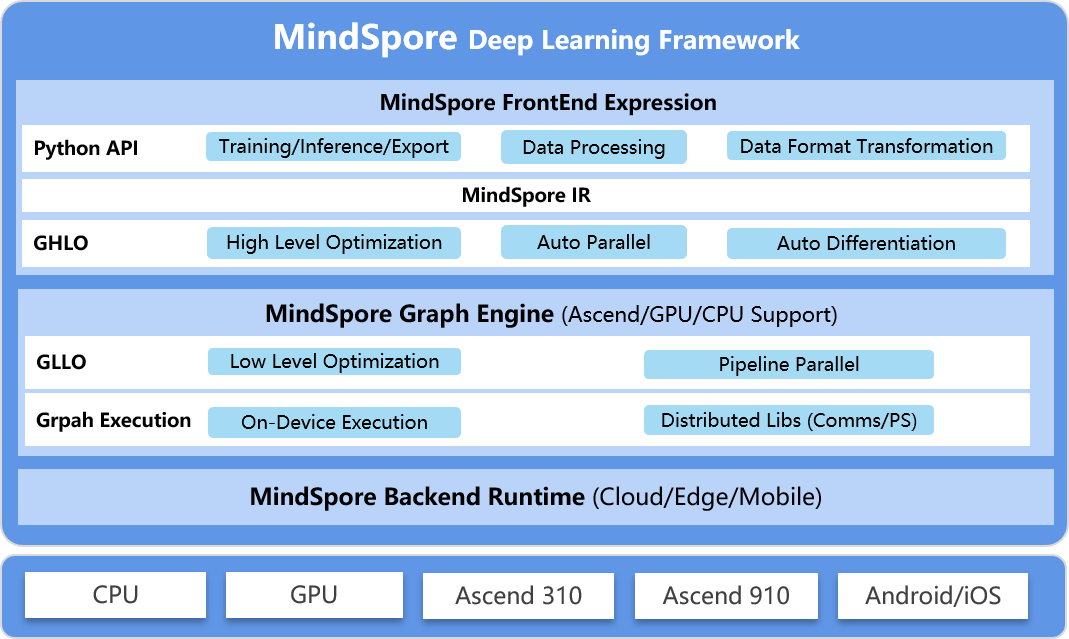
docs/MindSpore-architecture.png
0 → 100644
{kind=link}
53.0 KB
docs/MindSpore-logo.png
0 → 100644
{kind=link}
12.6 KB
docs/README.md
0 → 100644
example/Bert_NEZHA/config.py
0 → 100644
example/Bert_NEZHA/main.py
0 → 100644
example/lenet/config.py
0 → 100644
example/lenet/main.py
0 → 100644
example/resnet50_cifar10/eval.py
0 → 100755
example/resnet50_cifar10/train.py
0 → 100755
example/yolov3_coco2017/config.py
0 → 100644
example/yolov3_coco2017/train.py
0 → 100644
graphengine @ 5f763679
mindspore/__init__.py
0 → 100755
mindspore/_checkparam.py
0 → 100644
此差异已折叠。
mindspore/_extends/__init__.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/_extends/parse/trope.py
0 → 100644
此差异已折叠。
此差异已折叠。
mindspore/_extends/utils.py
0 → 100644
此差异已折叠。
mindspore/akg/__init__.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/__init__.py
0 → 100644
mindspore/akg/gpu/cast.py
0 → 100644
此差异已折叠。
此差异已折叠。
mindspore/akg/gpu/equal.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/mean.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/mean_grad.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/mul.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/relu6.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/relu6_grad.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/squeeze.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/squeeze_grad.py
0 → 100644
此差异已折叠。
mindspore/akg/gpu/tile.py
0 → 100644
此差异已折叠。
mindspore/akg/message.py
0 → 100644
此差异已折叠。
mindspore/akg/op_build.py
0 → 100644
此差异已折叠。
mindspore/akg/ops/__init__.py
0 → 100644
mindspore/akg/ops/array/tile.py
0 → 100644
此差异已折叠。
mindspore/akg/ops/math/cast.py
0 → 100644
此差异已折叠。
mindspore/akg/ops/math/equal.py
0 → 100644
此差异已折叠。
mindspore/akg/ops/math/mean.py
0 → 100644
此差异已折叠。
mindspore/akg/ops/math/mul.py
0 → 100644
此差异已折叠。
mindspore/akg/ops/math/sub.py
0 → 100644
此差异已折叠。
mindspore/akg/ops/math/sum.py
0 → 100644
此差异已折叠。
mindspore/akg/save_gpu_param.py
0 → 100644
此差异已折叠。
mindspore/akg/utils/__init__.py
0 → 100644
mindspore/akg/utils/dsl_create.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/CMakeLists.txt
0 → 100644
此差异已折叠。
mindspore/ccsrc/common.h
0 → 100644
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/common/trans.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/common/trans.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/common/utils.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/common/utils.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/debug/draw.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/draw.h
0 → 100644
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/debug/e2e_dump.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/e2e_dump.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/info.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/info.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/label.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/label.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/trace.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/debug/trace.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/ir/CMakeLists.txt
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/anf.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/anf.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/base.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/base.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/dtype.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/dtype.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/ir/dtype/empty.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/dtype/empty.h
0 → 100644
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/ir/dtype/number.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/dtype/ref.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/dtype/ref.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/dtype/type.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/dtype/type.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/func_graph.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/func_graph.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/ir/manager.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/manager.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/ir/meta_tensor.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/meta_tensor.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/named.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/named.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/primitive.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/primitive.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/scalar.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/scope.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/scope.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/signature.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/signature.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/value.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/value.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/visitor.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/ir/visitor.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/kernel/kernel.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/kernel/mng/recv.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/kernel/mng/send.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/mindspore.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/operator/ops.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/operator/ops.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/optimizer/clean.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/optimizer/cse.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/optimizer/cse.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/optimizer/opt.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/optimizer/opt.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/parallel/device.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/parallel/status.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/pipeline/action.h
0 → 100644
此差异已折叠。
mindspore/ccsrc/pipeline/init.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
mindspore/ccsrc/pipeline/pass.cc
0 → 100644
此差异已折叠。
mindspore/ccsrc/pipeline/pass.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。