增加函数优化方法笔记
Showing
book.json
0 → 100644
example/2.py
0 → 100644
example/calculus.py
0 → 100644
example/contingent_probability.py
0 → 100644
example/data/movie.csv
0 → 100644
因为 它太大了无法显示 source diff 。你可以改为 查看blob。
此差异已折叠。
example/data/tmdb_5000_movies.csv
0 → 100644
此差异已折叠。
example/fuliye.py
0 → 100644
example/movie_analyze.py
0 → 100644
example/stock.py
0 → 100644
homework/homework1.ipynb
0 → 100644
jupterbotebook/calculus.ipynb
0 → 100644
此差异已折叠。
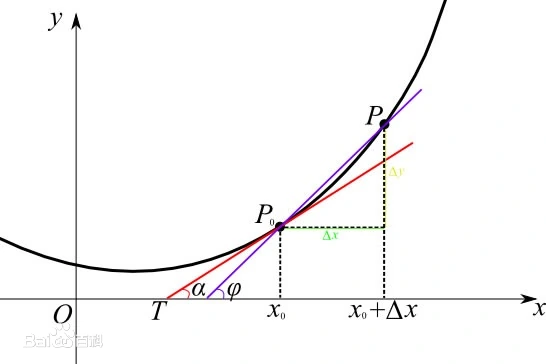
12.3 KB
jupterbotebook/imgs/ex.png
0 → 100644
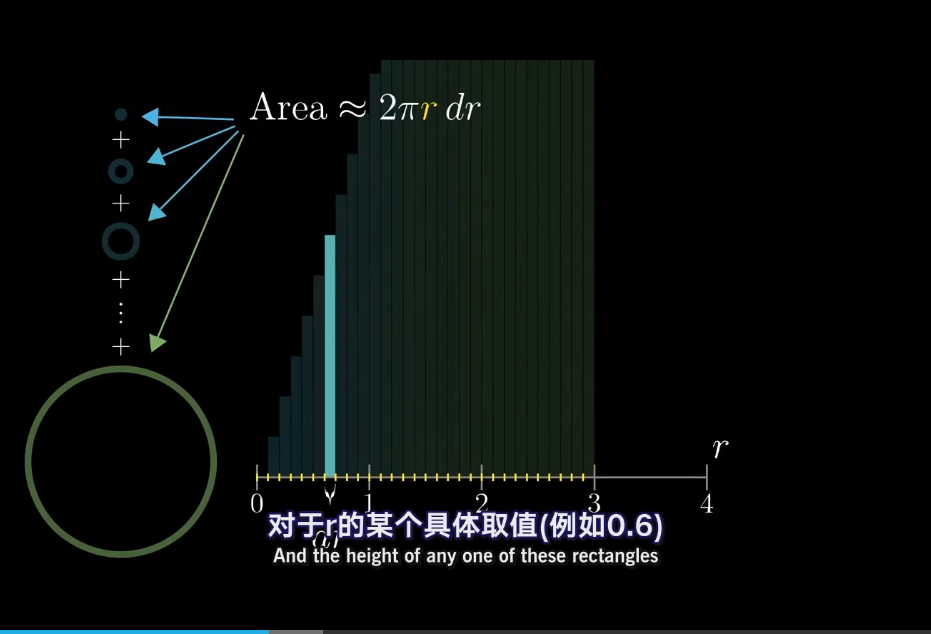
117.6 KB
jupterbotebook/imgs/gailv.png
0 → 100644

102.7 KB
此差异已折叠。
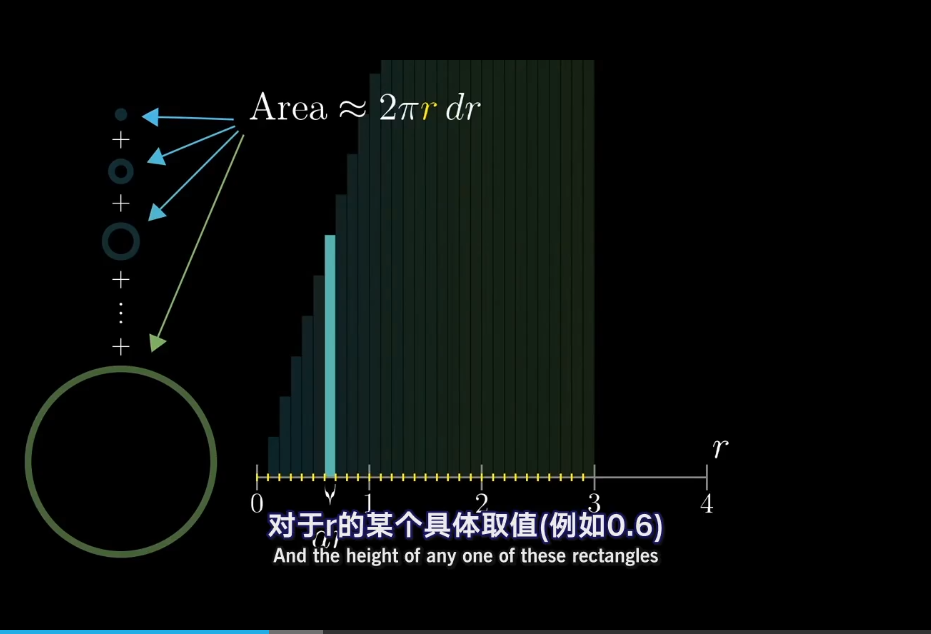
117.6 KB

102.7 KB
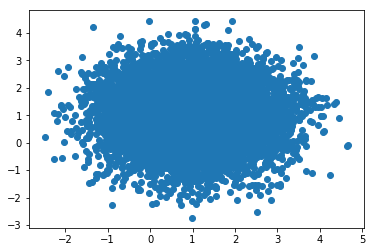
13.9 KB

5.6 KB
13.7 KB
10.1 KB

3.0 KB
3.6 KB

4.2 KB
probability_satatistics.md
0 → 100644
probability_satatistics.md.bak
0 → 100644
117.6 KB

102.7 KB
13.9 KB

13.7 KB
10.1 KB

3.0 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

4.2 KB
python_base/homework.md
0 → 100644