doc: add curve metric analyze
Signed-off-by: Nilixiaocui <ilixiaocui@163.com>
Showing
docs/cn/Curve块存储性能调优指南.md
0 → 100644
{kind=link}
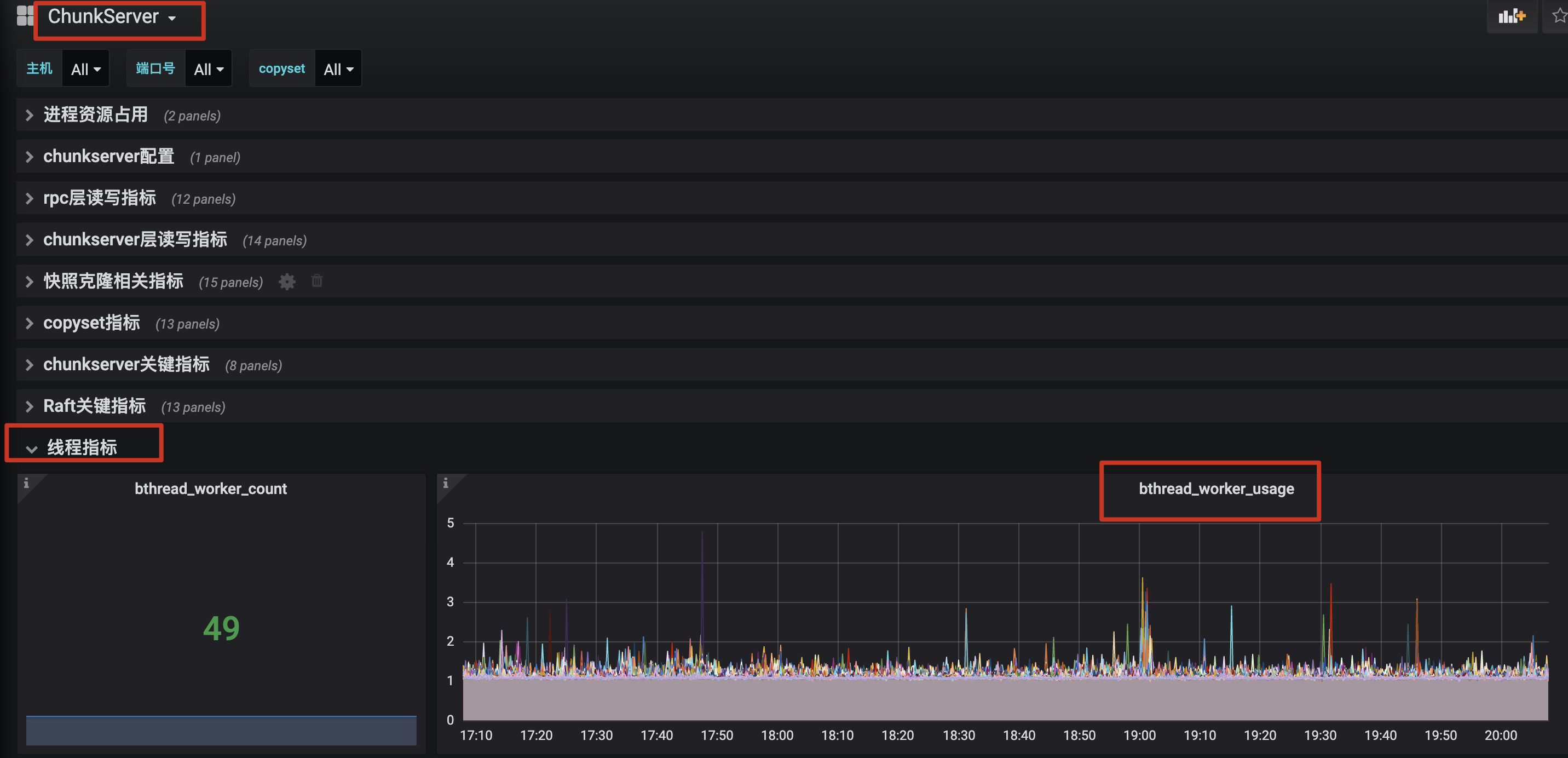
1.1 MB
{kind=link}

388.9 KB
docs/images/0102-diskcache1.jpg
0 → 100644
{kind=link}
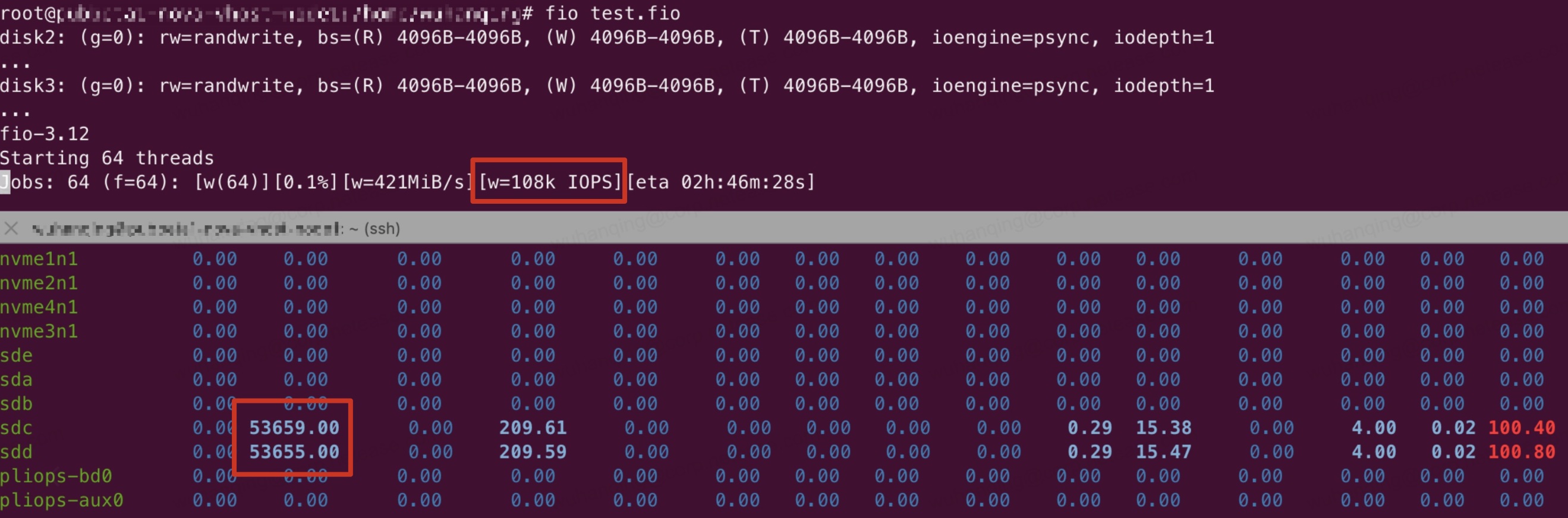
418.1 KB
docs/images/0102-diskcache2.jpg
0 → 100644
{kind=link}
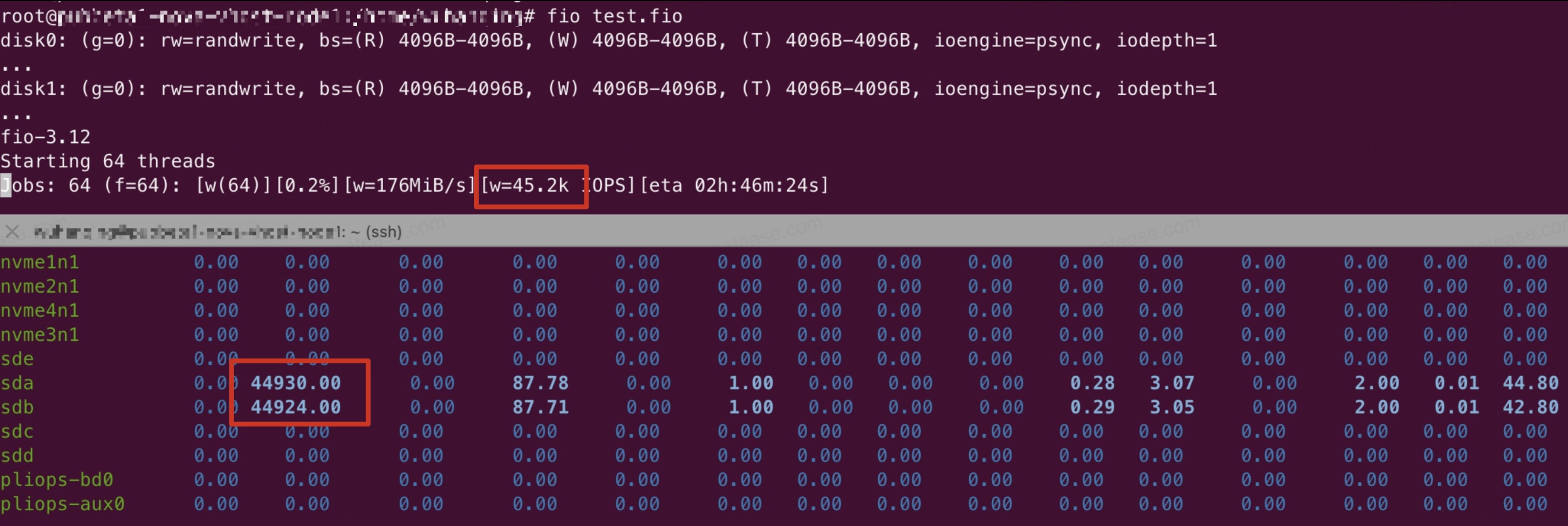
423.9 KB
{kind=link}
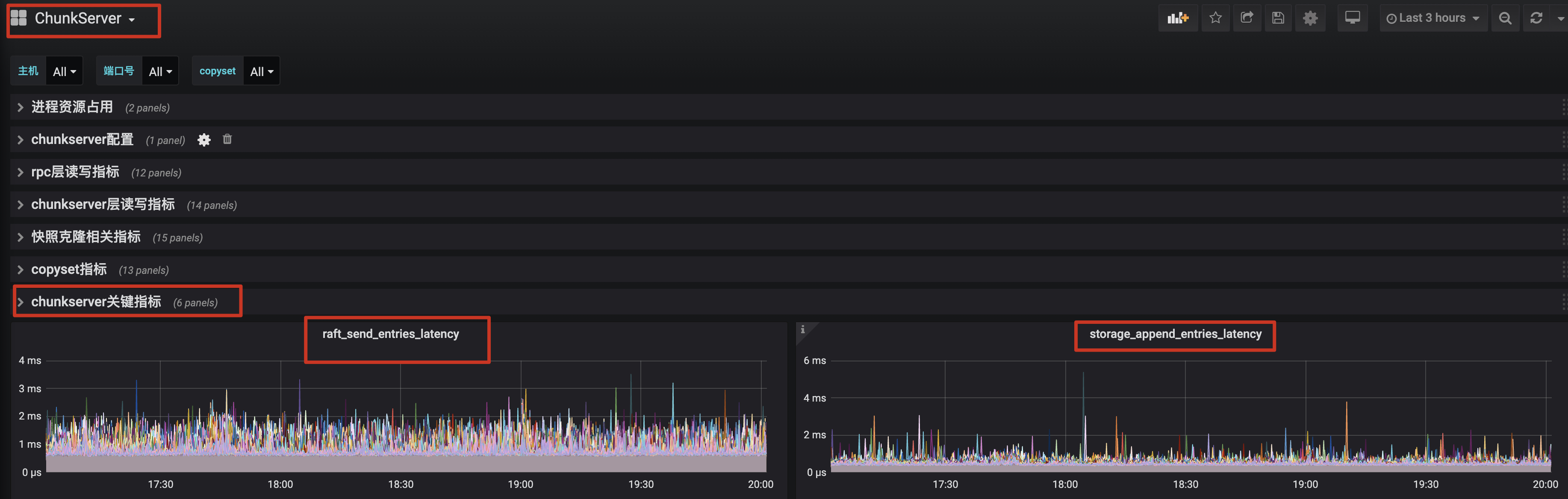
1.4 MB
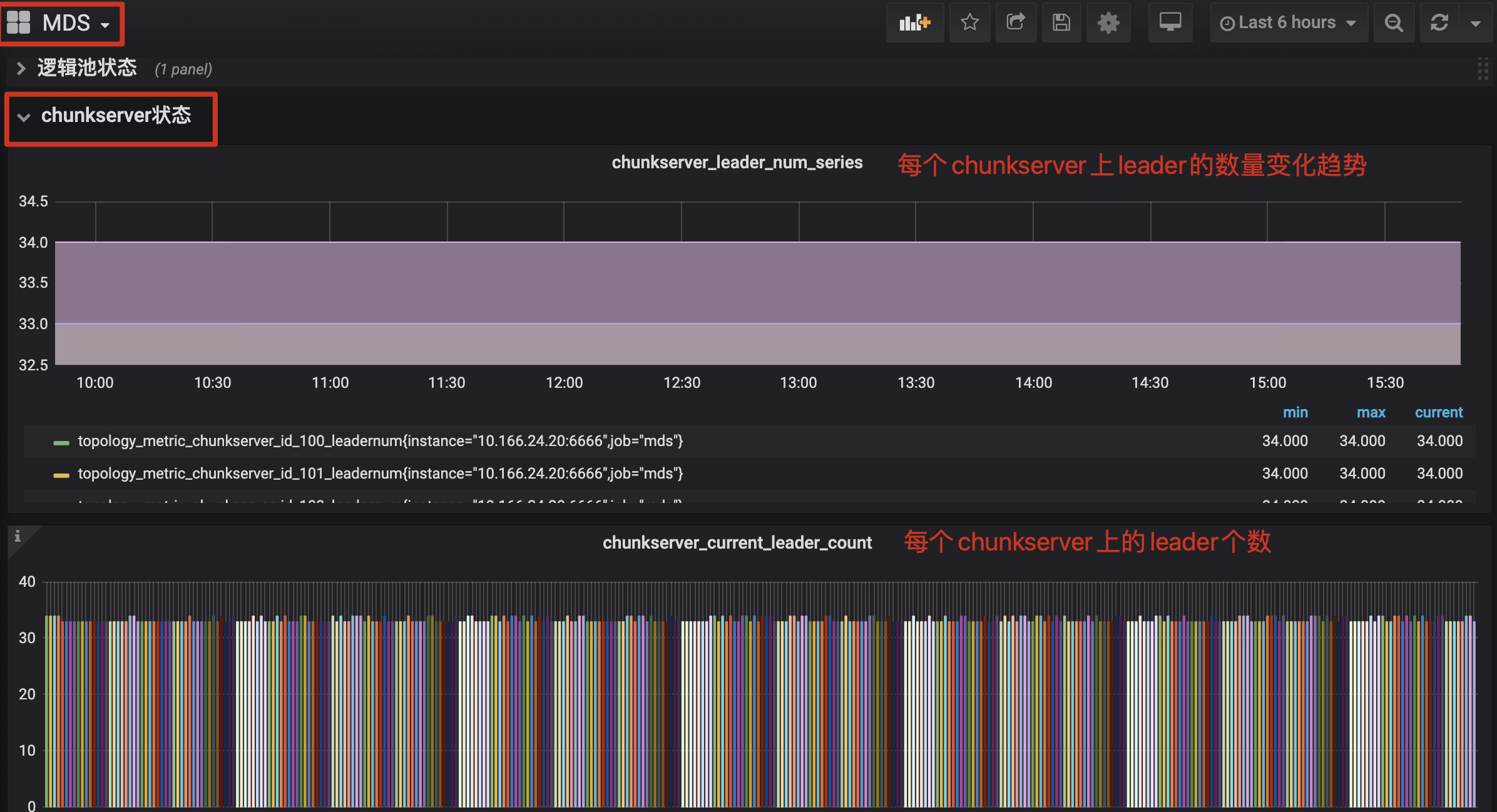
docs/images/0102-leadermetric.jpg
0 → 100644
{kind=link}
1.2 MB